Análise XML em Python
Este artigo se concentra em como é possível analisar um determinado arquivo XML e extrair alguns dados úteis de uma forma estruturada.
XML: XML significa eXtensible Markup Language. Ele foi projetado para armazenar e transportar dados. Ele foi projetado para ser legível tanto por humanos quanto por máquinas. É por isso que os objetivos de design do XML enfatizam a simplicidade, a generalidade e a usabilidade na Internet.
O arquivo XML a ser analisado neste tutorial é, na verdade, um feed RSS.
RSS: RSS (Rich Site Summary, frequentemente denominado Really Simple Syndication) usa uma família de formatos de feed da Web padrão para publicar informações atualizadas com frequência, como entradas de blog, manchetes de notícias, áudio e vídeo. RSS é texto simples formatado em XML.
- O formato RSS em si é relativamente fácil de ler tanto por processos automatizados quanto por humanos.
- O RSS processado neste tutorial é o feed RSS das principais notícias de um site de notícias popular. Você pode conferir aqui . Nosso objetivo é processar este feed RSS (ou arquivo XML) e salvá-lo em algum outro formato para uso futuro.
Módulo Python usado: Este artigo se concentrará no uso do módulo xml embutido em python para analisar XML e o foco principal será na API XML ElementTree deste módulo.
Implementação:
importcsvimportrequestsimportxml.etree.ElementTree as ETdefloadRSS():url='http://www.hindustantimes.com/rss/topnews/rssfeed.xml'resp=requests.get(url)withopen('topnewsfeed.xml','wb') as f:f.write(resp.content)defparseXML(xmlfile):tree=ET.parse(xmlfile)root=tree.getroot()newsitems=[]foriteminroot.findall('./channel/item'):news={}forchildinitem:ifchild.tag=='{http://search.yahoo.com/mrss/}content':news['media']=child.attrib['url']else:news[child.tag]=child.text.encode('utf8')newsitems.append(news)returnnewsitemsdefsavetoCSV(newsitems, filename):fields=['guid','title','pubDate','description','link','media']withopen(filename,'w') as csvfile:writer=csv.DictWriter(csvfile, fieldnames=fields)writer.writeheader()writer.writerows(newsitems)defmain():loadRSS()newsitems=parseXML('topnewsfeed.xml')savetoCSV(newsitems,'topnews.csv')if__name__=="__main__":main()
O código acima irá:
- Carregue o feed RSS do URL especificado e salve-o como um arquivo XML.
- Analise o arquivo XML para salvar notícias como uma lista de dicionários onde cada dicionário é um único item de notícias.
- Salve os itens de notícias em um arquivo CSV.
Vamos tentar entender o código em partes:
- Carregando e salvando feed RSS
def loadRSS(): # url do feed rss url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # criando objeto de resposta HTTP a partir do url fornecido resp = requests.get (url) # salvando o arquivo xml com open ('topnewsfeed.xml', 'wb') como f: f.write (resp.content)Aqui, primeiro criamos um objeto de resposta HTTP enviando uma solicitação HTTP para a URL do feed RSS. O conteúdo da resposta agora contém os dados do arquivo XML que salvamos como topnewsfeed.xml em nosso diretório local.
Para obter mais informações sobre como funciona o módulo de solicitações, siga este artigo:
Solicitações GET e POST usando Python
- Analisando XML
Criamos a função parseXML() para analisar o arquivo XML. Sabemos que XML é um formato de dados inerentemente hierárquico e a maneira mais natural de representá-lo é com uma árvore. Veja a imagem abaixo, por exemplo:
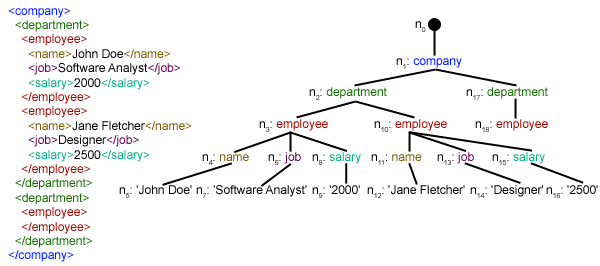
Aqui, estamos usando o módulo xml.etree.ElementTree (chame-o de ET, em resumo). A árvore de elementos possui duas classes para esse propósito - ElementTree representa todo o
documento XML como uma árvore e Element representa um único nó nessa árvore. As interações com todo o documento (leitura e gravação de / para arquivos) geralmente são feitas no nível ElementTree . As interações com um único elemento XML e seus subelementos são feitas no nível do Elemento .Ok, então vamos examinar a função parseXML() agora:
árvore = ET.parse (xmlfile)
Aqui, criamos um objeto ElementTree analisando o arquivo xml passado .
root = tree.getroot()
A função getroot() retorna a raiz da árvore como um objeto Element .
para item em root.findall ('./ channel / item'):Agora, depois de dar uma olhada na estrutura do seu arquivo XML, você notará que estamos interessados apenas no elemento item .
./channel/item é, na verdade, sintaxe XPath (XPath é uma linguagem para endereçar partes de um documento XML). Aqui, queremos encontrar todos os itens netos dos filhos do canal do raiz (denotados por '.').
Você pode ler mais sobre a sintaxe XPath com suporte aqui .
para item em root.findall ('./ channel / item'): # dicionário de notícias vazio notícias = {} # itera elementos filho do item para criança no item: # verificação especial para conteúdo de objeto de namespace: mídia if child.tag == '{http://search.yahoo.com/mrss/}content': news ['media'] = child.attrib ['url'] outro: notícias [child.tag] = child.text.encode ('utf8') # anexar dicionário de notícias à lista de itens de notícias newsitems.append (notícias)Agora, sabemos que estamos iterando por meio de elementos de item , onde cada elemento de item contém uma notícia. Assim, criamos um dicionário de notícias vazio no qual armazenaremos todos os dados disponíveis sobre a notícia. Para iterar cada elemento filho de um elemento, simplesmente iteramos por meio dele, assim:
para criança no item:
Agora, observe um elemento de item de amostra aqui:

Teremos que lidar com as tags de namespace separadamente conforme elas são expandidas para seu valor original, quando analisadas. Então, fazemos algo assim:
if child.tag == '{http://search.yahoo.com/mrss/}content': news ['media'] = child.attrib ['url']child.attrib é um dicionário de todos os atributos relacionados a um elemento. Aqui, estamos interessados no atributo url de media: tag de namespace de conteúdo .
Agora, para todas as outras crianças, simplesmente fazemos:notícias [child.tag] = child.text.encode ('utf8')child.tag contém o nome do elemento filho. child.text armazena todo o texto dentro desse elemento filho. Então, finalmente, um elemento de item de amostra é convertido em um dicionário e se parece com isto:
{'descrição': 'Ignis já tem uma competição acirrada, de Hyun ...., 'guid': 'http: //www.hindustantimes.com/autos/maruti-ignis-launch ...., 'link': 'http: //www.hindustantimes.com/autos/maruti-ignis-launch ...., 'media': 'http: //www.hindustantimes.com/rf/image_size_630x354/HT / ..., 'pubDate': 'Qui, 12 de janeiro de 2017 12:33:04 GMT', 'title': 'Maruti Ignis é lançado em 13 de janeiro: Cinco carros que ameaçam .....}Em seguida, simplesmente acrescentamos este elemento dict aos newsitems da lista .
Finalmente, esta lista é retornada. - Salvando dados em um arquivo CSV
Agora, simplesmente salvamos a lista de itens de notícias em um arquivo CSV para que possa ser usada ou modificada facilmente no futuro usando a função savetoCSV() . Para saber mais sobre como escrever elementos de dicionário em um arquivo CSV, leia este artigo:
Trabalhando com arquivos CSV em Python
Então, agora, aqui está como nossos dados formatados se parecem agora:

Como você pode ver, os dados do arquivo XML hierárquico foram convertidos em um arquivo CSV simples para que todas as notícias sejam armazenadas na forma de uma tabela. Isso também torna mais fácil estender o banco de dados.
Além disso, pode-se usar os dados do tipo JSON diretamente em seus aplicativos! Esta é a melhor alternativa para extrair dados de sites que não fornecem uma API pública, mas fornecem alguns feeds RSS.
Todos os códigos e arquivos usados no artigo acima podem ser encontrados aqui .
Qual o proximo?
- Você pode dar uma olhada em mais feeds rss do site de notícias usado no exemplo acima. Você pode tentar criar uma versão estendida do exemplo acima, analisando outros feeds rss também.
- Você é fã de críquete? Então este feed rss deve ser do seu interesse! Você pode analisar este arquivo XML para obter informações sobre as partidas de críquete ao vivo e usá-lo para fazer um notificador de desktop!
Este artigo foi contribuído por Nikhil Kumar. Se você gosta de GeeksforGeeks e gostaria de contribuir, você também pode escrever um artigo e enviá-lo para contrib@geeksforgeeks.org. Veja o seu artigo que aparece na página principal do GeeksforGeeks e ajude outros Geeks.
Escreva comentários se encontrar algo incorreto ou se quiser compartilhar mais informações sobre o tópico discutido acima

As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva