Buffer Lookaside de Tradução (TLB) em Paging
No Sistema Operacional (Técnica de Gerenciamento de Memória: Paginação ), para cada página de processo será criada uma tabela, que conterá a Entrada de Tabela de Página (PTE) . Este PTE conterá informações como o número do quadro (o endereço da memória principal onde queremos nos referir) e alguns outros bits úteis (por exemplo, bit válido / inválido, bit sujo, bit de proteção, etc.). Esta entrada de tabela de página (PTE) dirá onde na memória principal a página real está residindo.
Agora a questão é onde colocar a tabela de páginas, de forma que o tempo de acesso geral (ou tempo de referência) seja menor.
O problema inicial era acessar rapidamente o conteúdo da memória principal com base no endereço gerado pela CPU (ou seja, endereço lógico / virtual ). Inicialmente, algumas pessoas pensaram em usar registradores para armazenar tabela de páginas, pois são memórias de alta velocidade, então o tempo de acesso será menor.
A ideia usada aqui é, colocar as entradas da tabela de páginas em registradores, para cada solicitação gerada da CPU (endereço virtual), ela será correspondida ao número de página apropriado da tabela de páginas, que agora dirá onde na memória principal o correspondente a página reside. Tudo parece certo aqui, mas o problema é que o tamanho do registro é pequeno (na prática, pode acomodar no máximo 0,5k a 1k entradas de tabela de página) e o tamanho do processo pode ser grande, portanto, a tabela de página necessária também será grande (digamos esta página tabela contém 1M de entradas), portanto, os registradores podem não conter todos os PTEs da tabela de páginas. Portanto, esta não é uma abordagem prática.
Para superar esse problema de tamanho, toda a tabela de páginas foi mantida na memória principal. mas o problema aqui é que duas referências de memória principais são necessárias:
- Para encontrar o número do quadro
- Para ir para o endereço especificado pelo número do quadro
Para superar esse problema, um cache de alta velocidade é configurado para entradas da tabela de páginas, chamado Translation Lookaside Buffer (TLB). O Buffer Lookaside de tradução (TLB) nada mais é do que um cache especial usado para rastrear as transações usadas recentemente. TLB contém entradas de tabela de página que foram usadas mais recentemente. Dado um endereço virtual, o processador examina o TLB se uma entrada da tabela de páginas estiver presente (ocorrência de TLB), o número do quadro é recuperado e o endereço real é formado. Se uma entrada da tabela de página não for encontrada no TLB (falha de TLB), o número da página será usado como índice durante o processamento da tabela de página. O TLB primeiro verifica se a página já está na memória principal; se não estiver na memória principal, uma falha de página é emitida, então o TLB é atualizado para incluir a nova entrada de página.
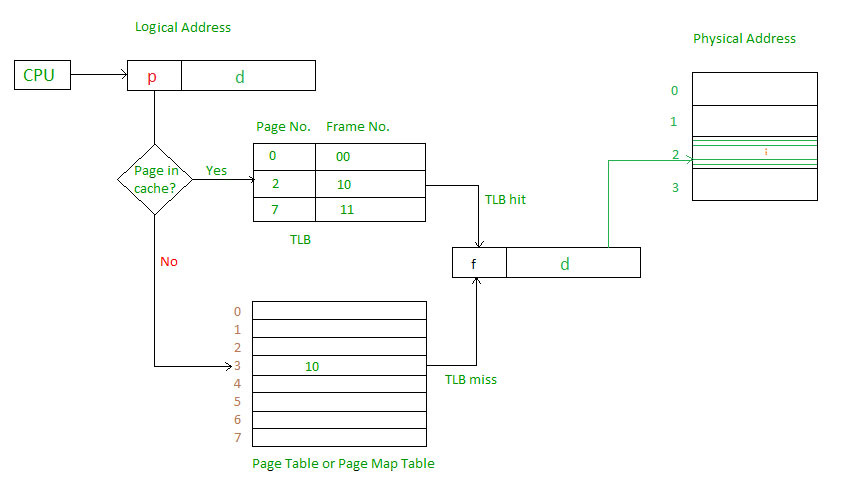
Etapas no hit TLB:
- CPU gera endereço virtual (lógico).
- É verificado em TLB (presente).
- O número do quadro correspondente é recuperado, o que agora indica onde está a página da memória principal.
Passos na TLB falham:
- CPU gera endereço virtual (lógico).
- É verificado em TLB (não presente).
- Agora, o número da página corresponde à tabela da página que reside na memória principal (assumindo que a tabela da página contém todos os PTE).
- O número do quadro correspondente é recuperado, o que agora indica onde está a página da memória principal.
- O TLB é atualizado com o novo PTE (se não houver espaço, uma das técnicas de substituição entra em cena, ou seja, FIFO, LRU ou MFU, etc.).
Tempo efetivo de acesso à memória (EMAT): TLB é usado para reduzir o tempo efetivo de acesso à memória, pois é um cache associativo de alta velocidade.
EMAT = h * (c + m) + (1-h) * (c + 2m)
onde, h = taxa de acerto de TLB
m = tempo de acesso à memória
c = tempo de acesso TLB
Aprenda todos os conceitos do GATE CS com aulas gratuitas ao vivo em nosso canal do youtube.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva