Como criar uma linguagem de programação usando Python?
Neste artigo, vamos aprender como criar sua própria linguagem de programação usando SLY (Sly Lex Yacc) e Python. Antes de nos aprofundarmos neste tópico, deve-se notar que este não é um tutorial para iniciantes e você precisa ter algum conhecimento dos pré-requisitos fornecidos abaixo.
Pré-requisitos
- Conhecimento aproximado sobre design de compiladores.
- Compreensão básica da análise lexical, análise sintática e outros aspectos do projeto do compilador.
- Compreensão de expressões regulares.
- Familiaridade com a linguagem de programação Python.
Começando
Instale SLY para Python. SLY é uma ferramenta de lexing e análise que torna nosso processo muito mais fácil.
pip install sly
Construindo um Lexer
A primeira fase de um compilador é converter todos os fluxos de caracteres (o programa de alto nível que é escrito) em fluxos de token. Isso é feito por um processo chamado análise lexical. No entanto, este processo é simplificado usando SLY
Primeiro, vamos importar todos os módulos necessários.
fromslyimportLexer
Agora vamos construir uma classe BasicLexer que estende a classe Lexer de SLY. Vamos fazer um compilador que faça operações aritméticas simples. Portanto, precisaremos de alguns tokens básicos, como NAME , NUMBER , STRING . Em qualquer linguagem de programação, haverá espaço entre dois caracteres. Assim, criamos um literal ignorar . Em seguida, também criamos os literais básicos como '=', '+' etc., os tokens NAME são basicamente nomes de variáveis, que podem ser definidos pela expressão regular [a-zA-Z _] [a-zA-Z0-9_] *. Os tokens STRING são valores de string e são delimitados por aspas (”“). Isso pode ser definido pela expressão regular \ ”. *? \”.
Sempre que encontrarmos dígito / s, devemos alocá-lo ao token NUMBER e o número deve ser armazenado como um inteiro. Estamos fazendo um script programável básico, então vamos apenas fazer com inteiros, no entanto, fique à vontade para estender o mesmo para decimais, longos etc., Também podemos fazer comentários. Sempre que encontramos “//”, ignoramos tudo o que vier a seguir nessa linha. Fazemos a mesma coisa com o caractere de nova linha. Assim, construímos um lexer básico que converte o fluxo de caracteres em fluxo de tokens.
classBasicLexer(Lexer):tokens={ NAME, NUMBER, STRING }ignore='\t 'literals={'=','+','-','/','*','(',')',',',';'}NAME=r'[a-zA-Z_][a-zA-Z0-9_]*'STRING=r'\".*?\"'@_(r'\d+')defNUMBER(self, t):t.value=int(t.value)returnt@_(r'//.*')defCOMMENT(self, t):pass@_(r'\n+')defnewline(self, t):self.lineno=t.value.count('\n')
Construindo um analisador
Primeiro, vamos importar todos os módulos necessários.
fromslyimportParser
Agora vamos construir uma classe BasicParser que estende a classe Lexer . O fluxo de tokens do BasicLexer é passado para tokens variáveis . A precedência é definida, que é a mesma para a maioria das linguagens de programação. A maior parte da análise escrita no programa abaixo é muito simples. Quando não há nada, a afirmação não passa nada. Basicamente, você pode pressionar Enter no teclado (sem digitar nada) e ir para a próxima linha. Em seguida, seu idioma deve compreender as atribuições usando o “=”. Isso é tratado na linha 18 do programa abaixo. A mesma coisa pode ser feita quando atribuída a uma string.
classBasicParser(Parser):tokens=BasicLexer.tokensprecedence=(('left','+','-'),('left','*','/'),('right','UMINUS'),)def__init__(self):self.env={ }@_('')defstatement(self, p):pass@_('var_assign')defstatement(self, p):returnp.var_assign@_('NAME "=" expr')defvar_assign(self, p):return('var_assign', p.NAME, p.expr)@_('NAME "=" STRING')defvar_assign(self, p):return('var_assign', p.NAME, p.STRING)@_('expr')defstatement(self, p):return(p.expr)@_('expr "+" expr')defexpr(self, p):return('add', p.expr0, p.expr1)@_('expr "-" expr')defexpr(self, p):return('sub', p.expr0, p.expr1)@_('expr "*" expr')defexpr(self, p):return('mul', p.expr0, p.expr1)@_('expr "/" expr')defexpr(self, p):return('div', p.expr0, p.expr1)@_('"-" expr %prec UMINUS')defexpr(self, p):returnp.expr@_('NAME')defexpr(self, p):return('var', p.NAME)@_('NUMBER')defexpr(self, p):return('num', p.NUMBER)
O analisador também deve analisar em operações aritméticas, isso pode ser feito por expressões. Digamos que você queira algo como o mostrado abaixo. Aqui, todos eles são transformados em fluxo de token linha por linha e analisados linha por linha. Portanto, de acordo com o programa acima, a = 10 é semelhante à linha 22. O mesmo para b = 20. a + b se assemelha à linha 34, que retorna uma árvore de análise ('add', ('var', 'a'), ('var', 'b')).
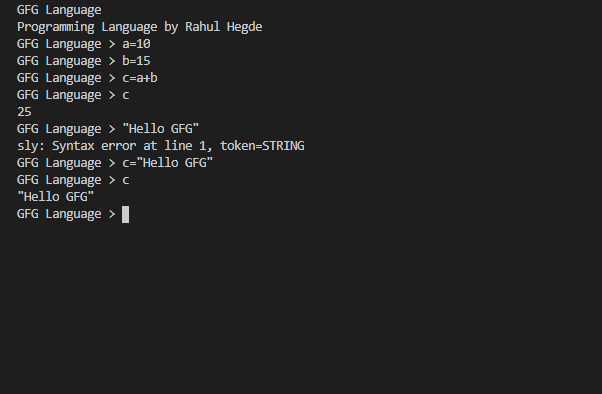
Idioma GFG> a = 10 Idioma GFG> b = 20 Idioma GFG> a + b 30
Agora convertemos os fluxos de token em uma árvore de análise. O próximo passo é interpretá-lo.
Execução
A interpretação é um procedimento simples. A ideia básica é pegar a árvore e percorrê-la para avaliar as operações aritméticas hierarquicamente. Este processo é chamado recursivamente repetidamente até que toda a árvore seja avaliada e a resposta seja recuperada. Digamos, por exemplo, 5 + 7 + 4. Este fluxo de caracteres é primeiro tokenizado para fluxo de tokens em um lexer. O fluxo de token é então analisado para formar uma árvore de análise. A árvore de análise essencialmente retorna ('adicionar', ('adicionar', ('num', 5), ('num', 7)), ('num', 4)). (veja a imagem abaixo)
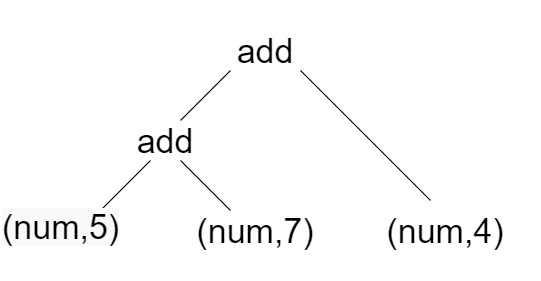
O interpretador vai adicionar 5 e 7 primeiro e, em seguida, chamar recursivamente walkTree e adicionar 4 ao resultado da adição de 5 e 7. Assim, obteremos 16. O código a seguir faz o mesmo processo.
classBasicExecute:def__init__(self, tree, env):self.env=envresult=self.walkTree(tree)ifresultisnotNoneandisinstance(result,int):(result)ifisinstance(result,str)andresult[0]=='"':(result)defwalkTree(self, node):ifisinstance(node,int):returnnodeifisinstance(node,str):returnnodeifnodeisNone:returnNoneifnode[0]=='program':ifnode[1]==None:self.walkTree(node[2])else:self.walkTree(node[1])self.walkTree(node[2])ifnode[0]=='num':returnnode[1]ifnode[0]=='str':returnnode[1]ifnode[0]=='add':returnself.walkTree(node[1])+self.walkTree(node[2])elifnode[0]=='sub':returnself.walkTree(node[1])-self.walkTree(node[2])elifnode[0]=='mul':returnself.walkTree(node[1])*self.walkTree(node[2])elifnode[0]=='div':returnself.walkTree(node[1])/self.walkTree(node[2])ifnode[0]=='var_assign':self.env[node[1]]=self.walkTree(node[2])returnnode[1]ifnode[0]=='var':try:returnself.env[node[1]]exceptLookupError:("Undefined variable '"+node[1]+"' found!")return0
Exibindo a saída
Para exibir a saída do interpretador, devemos escrever alguns códigos. O código deve primeiro chamar o lexer, depois o analisador e, em seguida, o interpretador e, finalmente, recuperar a saída. A saída é então exibida no shell.
if__name__=='__main__':lexer=BasicLexer()parser=BasicParser()('GFG Language')env={}whileTrue:try:text=input('GFG Language > ')exceptEOFError:breakiftext:tree=parser.parse(lexer.tokenize(text))BasicExecute(tree, env)
É necessário saber que não tratamos nenhum erro. Portanto, o SLY mostrará suas mensagens de erro sempre que você fizer algo que não esteja especificado nas regras que você escreveu.
Execute o programa que você escreveu usando,
python you_program_name.py
Notas de rodapé
O intérprete que construímos é muito básico. Isso, é claro, pode ser estendido para fazer muito mais. Loops e condicionais podem ser adicionados. Recursos de projeto modulares ou orientados a objetos podem ser implementados. Integração de módulo, definições de método, parâmetros para métodos são alguns dos recursos que podem ser estendidos aos mesmos.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva