Converter uma coluna em nome / índice de linha no Pandas
O Pandas oferece uma maneira conveniente de lidar com dados e sua transformação. Vamos ver como podemos converter uma coluna em nome / índice de linha no Pandas.
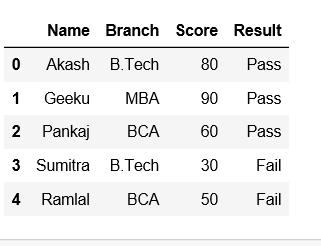
Crie um dataframe primeiro com listas de ditado.
# importing pandas as pd
import pandas as pd
# Creating a dict of lists
data = {'Name':["Akash", "Geeku", "Pankaj", "Sumitra","Ramlal"],
'Branch':["B.Tech", "MBA", "BCA", "B.Tech", "BCA"],
'Score':["80","90","60", "30", "50"],
'Result': ["Pass","Pass","Pass","Fail","Fail"]}
# creating a dataframe
df = pd.DataFrame(data)
dfSaída:
Método # 1: Usando o método set_index() .
# importing pandas as pd
import pandas as pd
# Creating a dict of lists
data = {'Name':["Akash", "Geeku", "Pankaj", "Sumitra","Ramlal"],
'Branch':["B.Tech", "MBA", "BCA", "B.Tech", "BCA"],
'Score':["80","90","60", "30", "50"],
'Result': ["Pass","Pass","Pass","Fail","Fail"]}
# Creating a dataframe
df = pd.DataFrame(data)
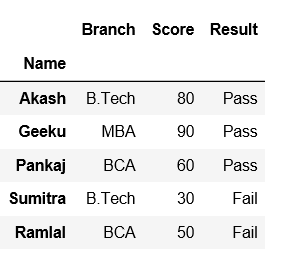
# Using set_index() method on 'Name' column
df = df.set_index('Name')
dfSaída:
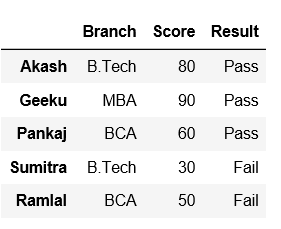
Agora, defina o nome do índice como Nenhum.
# set the index to 'None' via its name property
df.index.names = [None]
dfSaída:
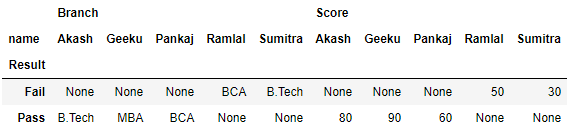
Método 2: Usando o método pivot() .
Para converter uma coluna em nome / índice de linha no dataframe, o Pandas tem uma função integrada Pivot.
Agora, digamos que queremos que Resultado seja as linhas / índice e as colunas sejam nomeadas em nosso dataframe, para conseguir isso, o pandas forneceu um método chamado Pivot. Vamos ver como funciona,
# importing pandas as pd
import pandas as pd
# Creating a dict of lists
data = {'name':["Akash", "Geeku", "Pankaj", "Sumitra", "Ramlal"],
'Branch':["B.Tech", "MBA", "BCA", "B.Tech", "BCA"],
'Score':["80", "90", "60", "30", "50"],
'Result': ["Pass", "Pass", "Pass", "Fail", "Fail"]}
df = pd.DataFrame(data)
# pivoting the dataframe
df.pivot(index ='Result', columns ='name')
dfSaída:
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva