Explicação do modelo BERT - PNL
BERT (Bidirectional Encoder Representations from Transformers) é um modelo de processamento de linguagem natural proposto por pesquisadores do Google Research em 2018. Quando foi proposto, ele alcançou precisão de ponta em muitas tarefas de PNL e NLU, como:
- Avaliação geral de compreensão da linguagem
- Conjunto de dados Stanford Q / A SQuAD v1.1 e v2.0
- Situação com gerações adversárias
Logo após alguns dias de lançamento, o código-fonte aberto publicado com duas versões do modelo pré-treinado BERT BASE e BERT LARGE que são treinados em um conjunto de dados massivo. O BERT também usa muitos algoritmos e arquiteturas de PNL anteriores, como treinamento semissupervisionado, transformadores OpenAI, ELMo Embeddings, ULMFit, Transformers.
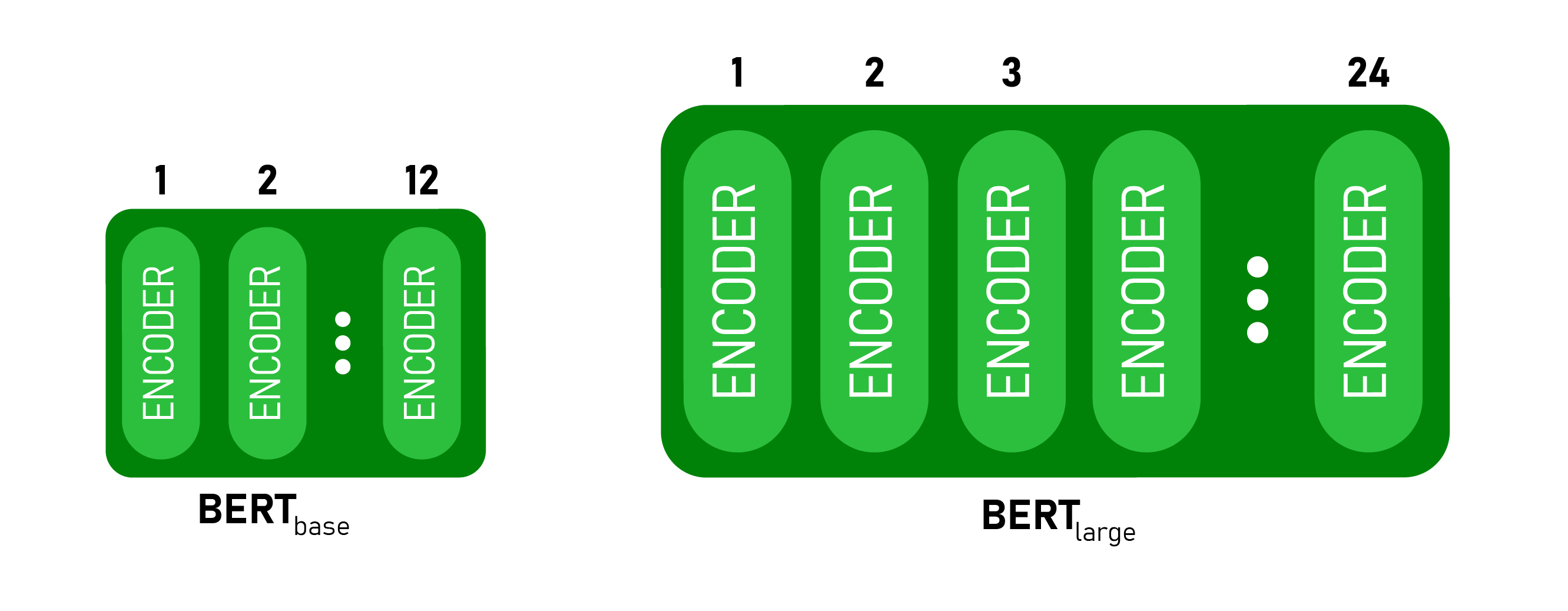
Arquitetura do modelo BERT: O
BERT é lançado em dois tamanhos, BERT BASE e BERT LARGE . O modelo BASE é usado para medir o desempenho da arquitetura comparável a outra arquitetura e o modelo LARGE produz resultados de última geração que foram relatados no artigo de pesquisa.
Aprendizagem Semi-Supervisionada:
Uma das principais razões para o bom desempenho do BERT em diferentes tarefas de PNL foi o uso da Aprendizagem Semi-Supervisionada . Isso significa que o modelo é treinado para uma tarefa específica que permite compreender os padrões da linguagem. Após o treinamento, o modelo (BERT) possui recursos de processamento de linguagem que podem ser usados para capacitar outros modelos que construímos e treinamos usando o aprendizado supervisionado.

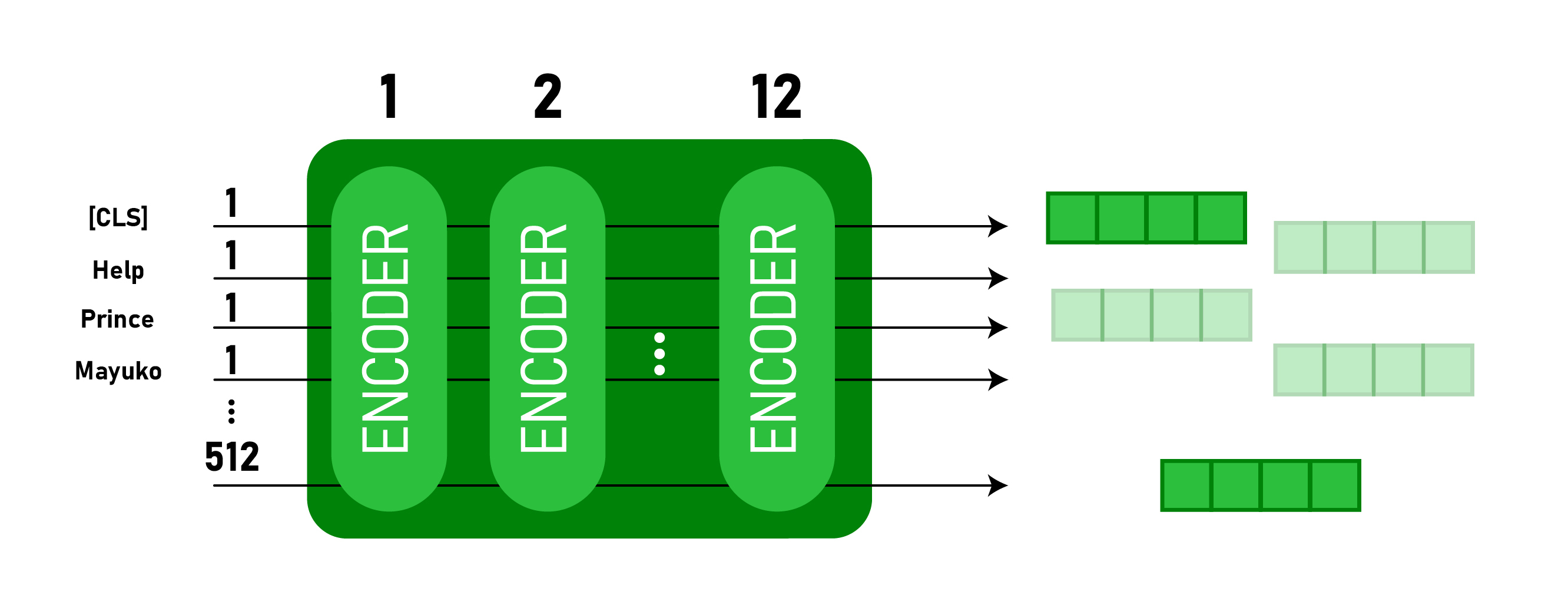
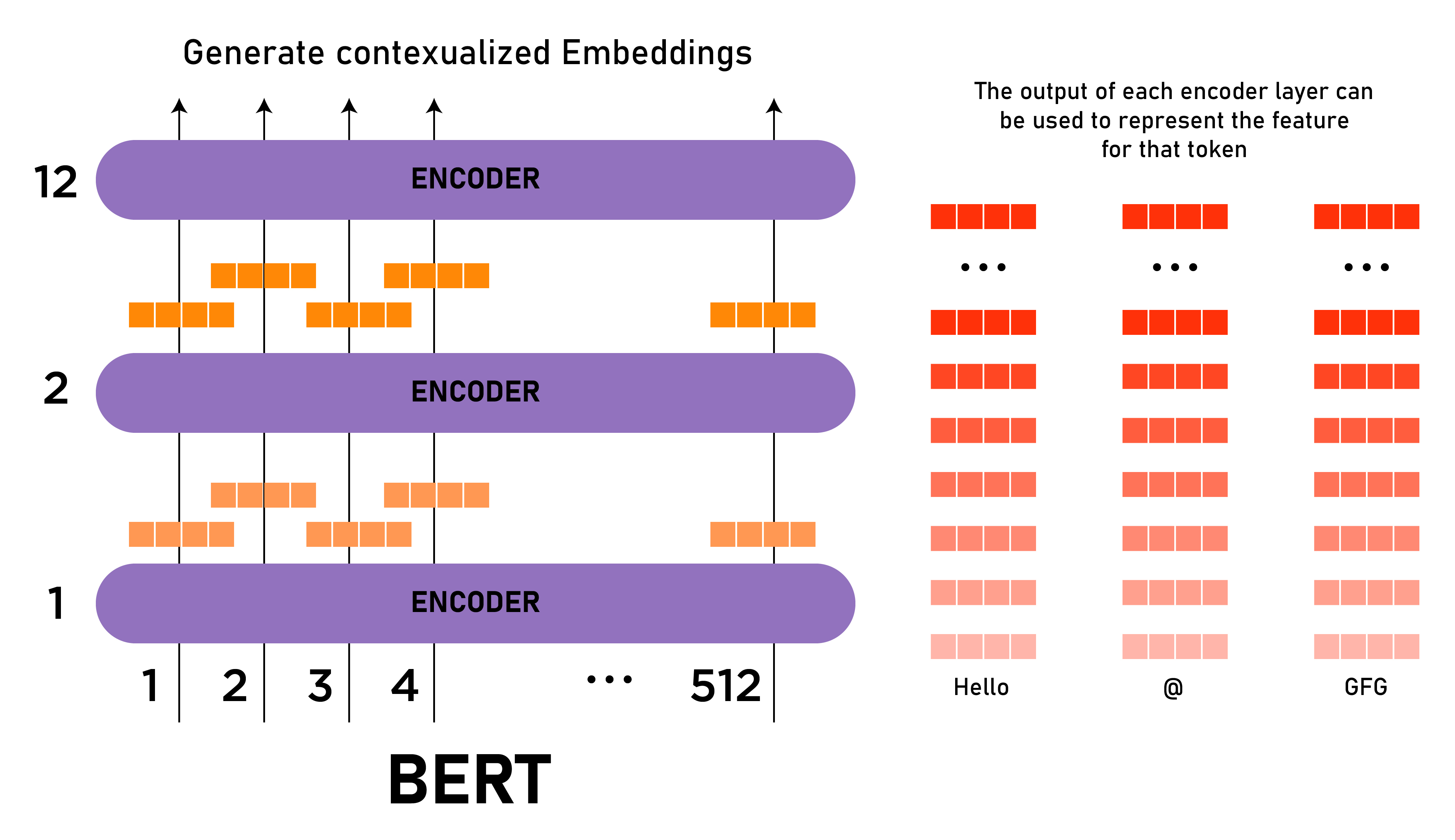
Este modelo usa o token CLS primeiro como entrada e, em seguida, é seguido por uma sequência de palavras como entrada. Aqui, CLS é um token de classificação. Em seguida, ele passa a entrada para as camadas acima. Cada camada aplica autoatenção, passa o resultado por uma rede feedforward e depois passa para o próximo codificador.
O modelo gera um vetor de tamanho oculto ( 768 para BERT BASE). Se quisermos gerar um classificador a partir desse modelo, podemos pegar a saída correspondente ao token CLS.
ELMo Word Embeddings:
este artigo é bom para recapitular o Word Embedding . Ele também discute Word2Vec e sua implementação. Basicamente, embeddings de palavras para uma palavra é a projeção de uma palavra em um vetor de valores numéricos com base em seu significado. Existem muitas palavras populares de incorporação, como Word2vec, GloVe, etc. ELMo era diferente dessas incorporações porque fornece incorporação a uma palavra com base em seu contexto, ou seja, incorporação de palavras contextualizadas. Para gerar a incorporação de uma palavra, o ELMo analisa a frase inteira em vez de uma incorporação fixa para uma palavra.
Elmo usa um LSTM bidirecional treinado para a tarefa específica para poder criar esses embeddings. Este modelo é treinado em um grande conjunto de dados na linguagem de nosso conjunto de dados e, então, podemos usá-lo como um componente em outras arquiteturas que são necessárias para realizar tarefas específicas de linguagem.
ULM-Fit: Transferência de Aprendizagem em PNL:
ULM-Fit apresenta um novo modelo de linguagem e processo para efetivamente ajustar esse modelo de linguagem para a tarefa específica. Isso permite que a arquitetura da PNL execute o aprendizado por transferência em um modelo pré-treinado semelhante ao executado em muitas tarefas de visão computacional.
Open AI Transformer: Pré-treinamento:
A arquitetura do Transformer acima pré-treinada apenas a arquitetura do codificador. Este tipo de pré-treinamento é bom para uma determinada tarefa, como tradução automática, etc., mas para tarefas como classificação de frases, esta abordagem de previsão da próxima palavra não funcionará. Nesta arquitetura, treinamos apenas o decodificador. Essa abordagem de decodificadores de treinamento funcionará melhor para a tarefa de previsão da próxima palavra porque mascara os tokens (palavras) futuros semelhantes a esta tarefa.
O modelo possui 12 pilhas de camadas do decodificador. Como não há codificador, essas camadas de decodificador têm apenas camadas de autoatenção.
Podemos treinar este modelo para a tarefa de modelagem de linguagem (previsão da próxima palavra), fornecendo-lhe uma grande quantidade de conjuntos de dados não rotulados, como uma coleção de livros, etc.
Previsão da palavra seguinte dos transformadores OpenAI
Agora que o transformador Open AI tem algum conhecimento da linguagem, ele pode ser usado para realizar tarefas posteriores, como classificação de frases. Abaixo está uma arquitetura para classificar uma frase como “Spam” ou “Não é Spam”.

Tarefa de classificação de frases de transformadores OpenAI
Resultados: O BERT fornece resultados ajustados para 11 tarefas de PNL. Aqui, discutimos alguns desses resultados em tarefas de PNL de referência.
- COLA:
A tarefa de Avaliação de Compreensão da Linguagem Geral é uma coleção de diferentes tarefas de Compreensão da Linguagem Natural. Estes incluem MNLI (Multi-Genre Natural Language Inference), QQP (Quora Question Pairs), QNLI (Question Natural Language Inference), SST-2 (The Stanford Sentiment Treebank), CoLA (Corpus of Linguistic Acceptability) etc. Ambos, BERT BASE e o BERT LARGE supera os modelos anteriores por uma boa margem (4,5% e 7% respectivamente). Abaixo estão os resultados de BERT BASE e BERT LARGE em comparação com outros modelos: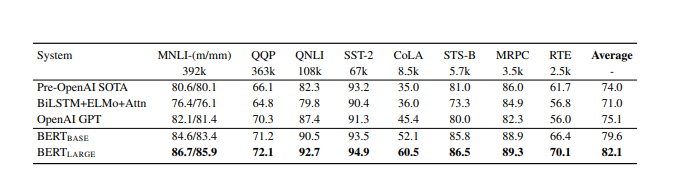
Resultado de BERT na tarefa GLUE NLP
- Conjunto de dados SQuAD v1.1
Stanford Pergunta Resposta O conjunto de dados é uma coleção de fonte de multidão de 100k Pergunta Resposta Pares. Um ponto de dados contém uma pergunta e uma passagem da Wikipedia que contém a resposta. A tarefa é prever a extensão do texto de resposta a partir da passagem.
O BERT de melhor desempenho (com o conjunto e TriviaQA) supera o sistema de classificação principal por 1,5 pontuação F1 no ensembling e 1,3 pontuação F1 como um sistema único. Na verdade, o único BERT BASE supera o sistema de conjunto de topo em termos de pontuação F1. - SWAG (Situations With Adversarial Generations) O
conjunto de dados SWAG contém 113k tarefas de conclusão de frase que avaliam a resposta de melhor ajuste usando uma inferência de senso comum fundamentada. Dada uma frase, a tarefa é escolher a continuação mais plausível entre quatro opções.
BERT LARGE supera o OpenAI GPT em 8,3%. Ele ainda tem um desempenho melhor do que um humano especialista.
O resultado do conjunto de dados SWAG é fornecido abaixo:
Resultados no conjunto de dados SWAG
Conclusão: O
BERT foi capaz de melhorar a precisão (ou pontuação F1) em muitas tarefas de Processamento de Linguagem Natural e Modelagem de Linguagem. O principal avanço que é fornecido por este artigo é permitir o uso de aprendizagem semissupervisionada para muitas tarefas de PNL que permitem a aprendizagem por transferência em PNL. Ele também é usado na pesquisa do Google, a partir de dezembro de 2019 era usado em 70 idiomas.
Abaixo estão alguns exemplos de consultas de pesquisa no Google Before and After using BERT.
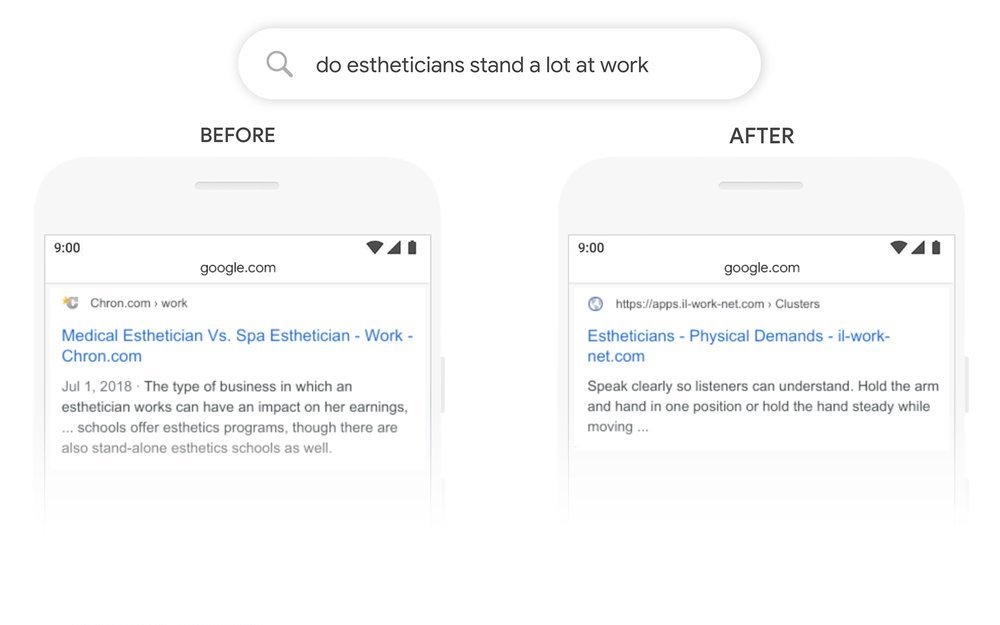
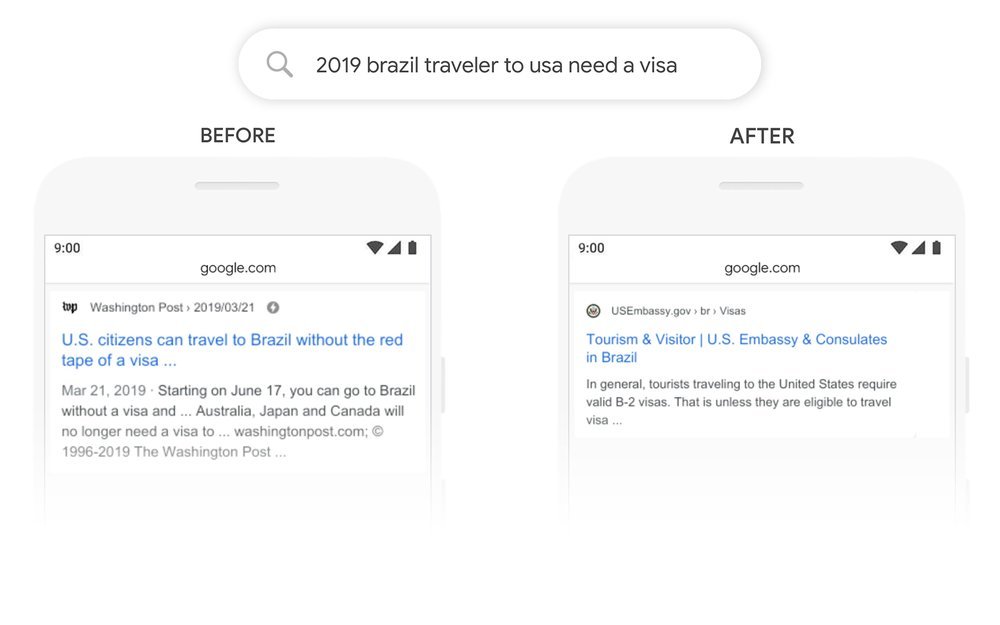
Referências:
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva