Filtrar Dataframe do Pandas com várias condições
Neste artigo, vamos discutir como filtrar dataframe do pandas com várias condições. Existem possibilidades de filtrar dados do dataframe Pandas com múltiplas condições durante todo o desenvolvimento do software. O motivo é que o dataframe pode ter várias colunas e várias linhas. A exibição seletiva de colunas com linhas limitadas é sempre a visão esperada dos usuários. Para atender às expectativas do usuário e também ajudar em cenários de aprendizado profundo de máquina, a filtragem de dataframe do Pandas com várias condições é muito necessária.
Vamos ver as diferentes maneiras de fazer o mesmo.
Criação de um dataframe de amostra para prosseguir
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# display dataframe
display(dataFrame)Saída:
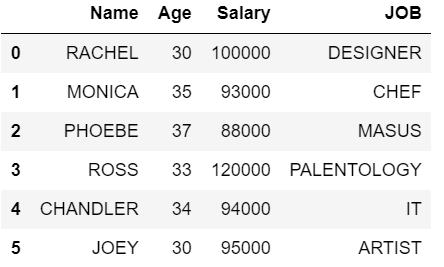
Método 1: usando loc
Aqui, obteremos todas as linhas com Salário maior ou igual a 100000 e Idade <40 e seu JOB começa com 'D' do dataframe. Imprima os detalhes com Nome e seu TRABALHO. Para o requisito acima, podemos conseguir isso usando loc . É usado para acessar uma ou mais linhas e colunas por rótulo (s) ou por um array booleano. loc funciona com rótulos e índices de coluna.
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
display(dataFrame.loc[(dataFrame['Salary']>=100000) & (dataFrame['Age']< 40) & (dataFrame['JOB'].str.startswith('D')),
['Name','JOB']])Saída:
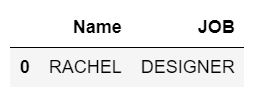
A saída é resolvida para as condições fornecidas e, finalmente, vamos mostrar apenas 2 colunas, a saber, Nome e JOB.
Método 2: Usando NumPy
Aqui obterá todas as linhas com Salário maior ou igual a 100.000 e Idade <40 e seu TRABALHO começa com 'D' no quadro de dados. Precisamos usar o NumPy.
# import module
import pandas as pd
import numpy as np
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
filtered_values = np.where((dataFrame['Salary']>=100000) & (dataFrame['Age']< 40) & (dataFrame['JOB'].str.startswith('D')))
print(filtered_values)
display(dataFrame.loc[filtered_values])Saída:
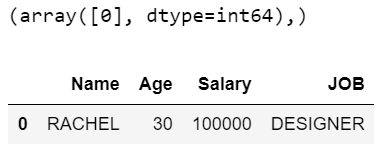
No exemplo acima, print (filter_values) dará a saída como (array ([0], dtype = int64),) que indica que a primeira linha com valor de índice 0 será a saída. Depois disso, a saída terá 1 linha com todas as colunas e é recuperada de acordo com as condições fornecidas.
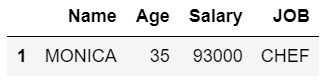
Método 3: usando consulta (avaliação e consulta funcionam apenas com colunas)
Nesta abordagem, obtemos todas as linhas com Salário menor ou igual a 100000 e Idade <40, e seu JOB começa com 'C' no dataframe. Basta consultar as colunas de um DataFrame com uma ou mais expressões booleanas e, se forem múltiplas, terá uma condição & no meio.
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
display(dataFrame.query('Salary <= 100000 & Age < 40 & JOB.str.startswith("C").values'))Saída:
Método 4: indexação booleana do pandas de múltiplas condições de maneira padrão (a “indexação booleana” funciona com valores em apenas uma coluna)
Nesta abordagem, obtemos todas as linhas com Salário menor ou igual a 100000 e Idade <40 e seu JOB começa com 'P' do dataframe. Para selecionar o subconjunto de dados usando os valores no dataframe e aplicando as condições booleanas, precisamos seguir estas maneiras
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
display(dataFrame[(dataFrame['Salary']>=100000) & (dataFrame['Age']<40) & dataFrame['JOB'].str.startswith('P')][['Name','Age','Salary']])Saída:

Estamos mencionando uma lista de colunas que precisam ser recuperadas junto com as condições booleanas e, como muitas condições, tem '&'.
Método 5: avaliação de várias condições (“eval” e “consulta” funcionam apenas com colunas)
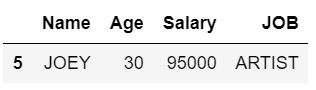
Aqui, obtemos todas as linhas com Salário menor ou igual a 100000 e Idade <40 e seu JOB começa com 'A' do dataframe.
# import module
import pandas as pd
# assign data
dataFrame = pd.DataFrame({'Name': [' RACHEL ', ' MONICA ', ' PHOEBE ',
' ROSS ', 'CHANDLER', ' JOEY '],
'Age': [30, 35, 37, 33, 34, 30],
'Salary': [100000, 93000, 88000, 120000, 94000, 95000],
'JOB': ['DESIGNER', 'CHEF', 'MASUS', 'PALENTOLOGY',
'IT', 'ARTIST']})
# filter dataframe
display(dataFrame[dataFrame.eval("Salary <=100000 & (Age <40) & JOB.str.startswith('A').values")])Saída:
Dataframes são um conceito muito essencial em Python e a filtragem de dados necessária pode ser realizada com base em várias condições. Eles podem ser alcançados de qualquer uma das maneiras acima. Ponts a serem observados:
- loc funciona com rótulos e índices de coluna.
- eval e query funcionam apenas com colunas.
- A indexação booleana funciona apenas com valores em uma coluna.
Atenção geek! Fortaleça suas bases com o Python Programming Foundation Course e aprenda o básico.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva