GPT de imagem
A GPT de imagem foi proposta por pesquisadores da OpenAI em 2019. Este artigo experimenta a aplicação de transformação semelhante à GPT nas tarefas de reconhecimento / detecção de objetos. No entanto, existem alguns desafios enfrentados pelos autores, como o processamento de grandes tamanhos de imagem, etc.
Arquitetura:
A arquitetura do Image GPT (iGPT) é semelhante ao GPT-2, ou seja, é composto de um bloco de decodificador de transformador. O decodificador do transformador pega uma sequência de entrada x 1 ,…, x n de tokens discretos e emite uma incorporação d-dimensional para cada posição. O transformador pode ser considerado como uma pilha de decodificadores de tamanho L , o l-ésimo dos quais produz uma incorporação de h 1 l … .h n l . Depois disso, o tensor de entrada é passado para diferentes camadas da seguinte forma:
- n l = layer_norm ( h l )
- a l = h l + atenção de várias cabeças ( n l )
- h l + 1 = a l + mlp (norma da camada (a l ))
Onde layer_norm é a normalização da camada e a camada MLP é um modelo perceptron de várias camadas (rede neural artificial). Abaixo está a lista de diferentes versões
| Nome do modelo / variante | Resolução de entrada | params (M) | Recursos |
|---|---|---|---|
| iGPT-Large (L) | 32 * 32 * 3 | 1362 | 1536 |
| 48 * 48 * 3 | |||
| iGPT-XL | 64 * 64 * 3 | 6801 | 3072 |
| 15360 |
Redução de contexto:
Porque os requisitos de memória do decodificador do transformador escalam quadraticamente com o comprimento do contexto ao usar atenção densa. Isso significa que é preciso muita computação para treinar até mesmo um transformador de camada única. Para lidar com isso, os autores redimensionam a imagem para resoluções mais baixas, chamadas de resoluções de entrada (IRs). O modelo iGPT usa IRs de 32 * 32 * 3 , 48 * 48 * 3 e 64 * 64 * 3 .
Metodologia de treinamento:
O treinamento do modelo de GPT de imagens consiste em duas etapas:
Pré treino
- Dado um conjunto de dados não rotulado X consistindo em dados dimensionais elevados x = (x 1 , ..., x n ), podemos escolher uma permutação π do conjunto [1, n] e modelar a densidade p (x) auto-regressivamente da seguinte forma:
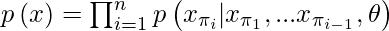
- Para imagens, escolhemos a permutação de identidade π i = i para 1 ≤ i ≤ n, também conhecida como ordem raster. O modelo é treinado para minimizar a probabilidade de log negativo:
![L_ {AR} = \ mathbb {E} _ {x \ sim X} \ left [-log \ left (p (x) \ right) \ right]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-20d04adca1c6032b08205c45bd5dcbaa_l3.png)
- Os autores também usaram a função de perda semelhante à modelagem de linguagem mascarada em BERT, que mostra uma sub-sequência M ⊂ [1, n] de modo que cada índice i independentemente tem probabilidade de 0,15 de aparecer em M.
![L_ {BERT} = \ mathbb {E} _ {x \ sim X} \ mathbb {E} _ {M} \ left [-log \ left (p (x_i | x _ {[1, n] \ barra invertida M}) \certo, certo ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-cd195db2c0eab5c6c4d788983397b74b_l3.png)
- Durante o pré-treinamento, escolhemos um dos L AR ou L BERT e minimizamos a perda em relação ao nosso conjunto de dados pré-treinamento.
Afinação:
- Para o ajuste fino, os autores realizaram pool médio n L em toda a dimensão de sequência para extrair um vetor d-dimensional de recursos por exemplo e aprender uma projeção da camada de pool média. Os autores usaram essa projeção para minimizar a perda de entropia cruzada L CLF . Isso faz com que a função objetivo total
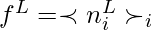
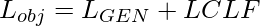
- Onde L GEN é L AR ou L BERT .
Os autores também experimentaram com sondagem linear que é semelhante ao ajuste fino, mas sem qualquer camada de pooling média.
Resultados:
- No CIFAR-10, o iGPT-L atinge 99,0% de precisão e no CIFAR-100, atinge 88,5% de precisão após o ajuste fino. O iGPT-L supera o AutoAugment, o modelo mais bem supervisionado nesses conjuntos de dados.
- No ImageNet, o iGPT atinge uma precisão de 66,3% após o ajuste fino em MR (resolução de entrada / resolução de memória) 32 * 32 , uma melhoria de 6% em relação à medição linear. Ao fazer o ajuste fino em MR 48 * 48 , o modelo alcançou 72,6% de precisão, com uma melhoria semelhante de 7% em relação à medição linear.
Referências:
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva