Gráficos interativos usando o pacote Pywedge
No aprendizado de máquina e na ciência de dados, uma das tarefas mais difíceis é entender os dados brutos e torná-los adequados para a aplicação de diferentes modelos sobre eles para fazer previsões. Para fins de compreensão, fazemos uso de diferentes processos, como verificar números estatísticos, como média, mediana, modo, encontrar a relação entre recursos, observar a distribuição de certos recursos, etc. Tudo isso é frequentemente denominado Análise Exploratória de Dados (EDA) . De acordo com profissionais experientes de ML e DS, EDA é uma das tarefas mais valiosas e sua importância não pode ser negligenciada quando se trata de analisar o conjunto de dados. Ajuda os profissionais a escolher as técnicas de pré-processamento de dados apropriadas.
Verificar os números estatísticos é muito bom, mas o que é melhor do que visualizar essas estatísticas pictoricamente, muitas vezes se diz que as imagens são uma ferramenta mais poderosa para a compreensão do que apenas números numéricos. Podemos obter uma compreensão mais clara dos dados visualmente, criando gráficos diferentes. Em aprendizado de máquina e ciência de dados, usamos diferentes tipos de gráficos / plotagens para visualizar diferentes padrões entre os recursos, alguns dos quais são: histograma, gráficos de barras, gráficos de caixa, gráficos de pares, gráficos de pizza, gráficos de violino, etc. Mas escrever códigos manualmente para todos esses gráficos / plotagens podem parecer um processo cansativo e também estamos mais sujeitos a imprecisões e erros / bugs no código. Então, aí vem nosso salva-vidas, um pacote python que realiza as tarefas de plotar esses gráficos de maneira fácil e eficiente, sem nenhum desses bugs no código.
Neste artigo, estaremos lendo sobre como fazer plotagens / gráficos interativos usando o pacote pywedge python. Pywedge é um pacote python de código aberto que pode ser usado para automatizar a maioria das tarefas de resolução de problemas de aprendizado de máquina. Ele também nos oferece recursos para traçar gráficos interativos usando apenas algumas linhas de código.
A biblioteca Pywedge tem um método make_charts que nos oferece a criação de 8 tipos diferentes de gráficos que são nomeados da seguinte forma:
- Gráfico de dispersão
- Gráfico de pizza
- Bar Plot
- Trama de violino
- Box plot
- Gráfico de distribuição
- Histograma
- Gráfico de correlação
Vamos ver um exemplo de como podemos usar a biblioteca pywedge para desenhar gráficos interativos:
Importando bibliotecas e carregando o conjunto de dados:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("https://www.shortto.com/WineDataset",sep=";")Depois de carregar o conjunto de dados, veremos como o conjunto de dados se parece, isso pode ser visto usando o método head para imprimir as 5 linhas principais no conjunto de dados:
df.head()

print("Shape of our dataframe is: ",df.shape)
Shape of our dataframe is: (1599, 12)
Portanto, como podemos notar, temos um total de 1599 linhas e 11 recursos no conjunto de dados, juntamente com um recurso de destino denominado 'qualidade'.
É sempre melhor verificar algumas estatísticas sobre nosso conjunto de dados e podemos fazer isso usando o método describe() como:
df.describe()
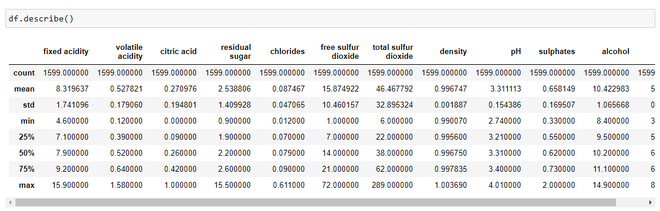
Estatísticas sobre o conjunto de dados
Olhando apenas para as estatísticas, podemos inferir
- O valor médio é maior do que o valor mediano em cada uma das colunas, por exemplo, o valor médio do pH é 3,311113, enquanto o valor mediano é 3,310000. Da mesma forma, a média do álcool é 10,422 em comparação com a mediana que é 10,20.
- Podemos notar uma grande diferença entre o valor do 75º percentil e os valores máximos dos preditores “açúcar residual”, “dióxido de enxofre livre”, “dióxido de enxofre total”. Isso indica que alguns valores dessas 3 variáveis estão muito mais distantes da faixa geral de valores (até 75% do bloco). Assim, podemos concluir que existem valores extremos, ou seja, Outliers em nosso conjunto de dados.
Renomeação da coluna e divisão do conjunto de dados:
df.rename(columns={'ficxed acidity':'fixed_acidity','citric acid':'citric_acid',
'volatile acidity':'volatile_acidity','residual sugar':'residual_sugar',
'free sulphur dioxide':'free_sulphur_dioxide',
'total sulphur dioxide': 'total_sulphur_dioxide'},inplace=True)
# Splitting data into features and labels set
X = df.iloc[:,:11]
y = df.iloc[:,-1]
Usando a biblioteca Pywedge para fazer gráficos:
import pywedge as pw
charts = pw.Pywedge_Charts(df, c=None, y = 'quality')
# Calling the make_charts method
plots = charts.make_charts()O método 'make_charts' na execução produz uma janela que nos dá 8 tipos diferentes de opções de gráfico e podemos selecionar nossos recursos necessários para traçar o gráfico e visualizar os resultados.
Fazendo um gráfico de dispersão:
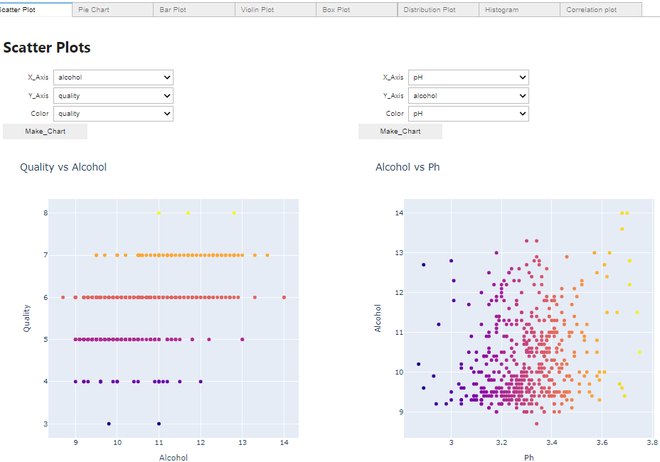
Gráfico de dispersão
Fazendo um enredo de violino:
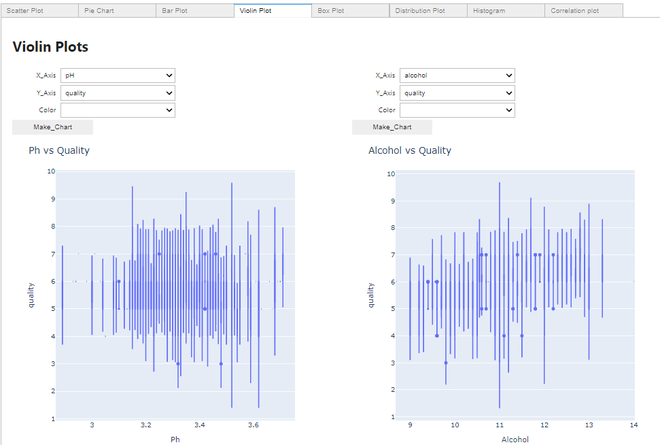
Trama de violino
Fazendo um gráfico de distribuição:
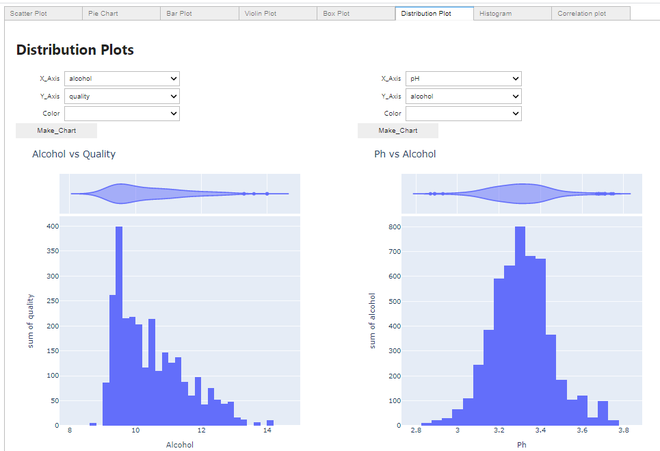
Gráfico de distribuição
Fazendo um Histograma:
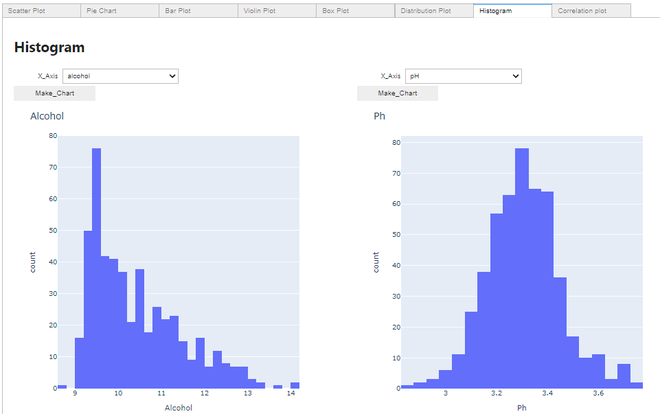
Histograma
Fazendo um gráfico de correlação:
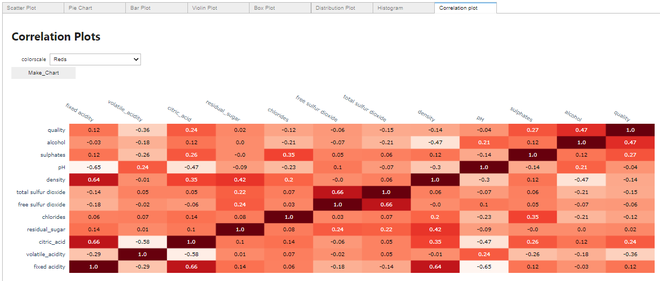
Gráfico de correlação
Assim, podemos ver com que eficiência podemos plotar esses vários gráficos usando apenas algumas linhas de código usando o pacote pywedge sem escrever códigos explicitamente para todos esses gráficos.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva