Inserir operação na árvore B
No post anterior , apresentamos o B-Tree. Também discutimos as funções search() e traverse().
Neste post, a operação insert() é discutida. Uma nova chave é sempre inserida no nó folha. Seja a chave a ser inserida k. Como o BST, começamos da raiz e descemos até chegar a um nó folha. Assim que chegarmos a um nó folha, inserimos a chave nesse nó folha. Ao contrário dos BSTs, temos um intervalo predefinido no número de chaves que um nó pode conter. Portanto, antes de inserir uma chave para o nó, certificamo-nos de que o nó possui espaço extra.
Como ter certeza de que um nó tem espaço disponível para uma chave antes que a chave seja inserida? Usamos uma operação chamada splitChild() que é usada para dividir um filho de um nó. Veja o diagrama a seguir para entender a divisão. No diagrama a seguir, o filho y de x está sendo dividido em dois nós y e z. Observe que a operação splitChild move uma tecla para cima e esta é a razão pela qual as árvores B crescem, ao contrário dos BSTs que crescem para baixo.
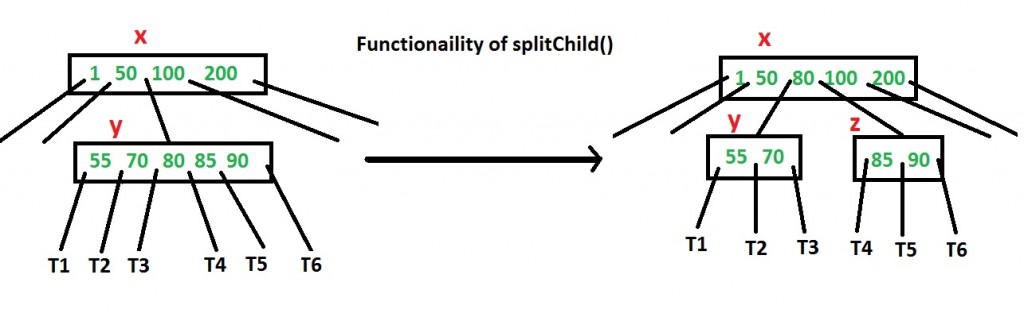
Conforme discutido acima, para inserir uma nova chave, vamos descer da raiz à folha. Antes de descer para um nó, primeiro verificamos se o nó está cheio. Se o nó estiver cheio, nós o dividimos para criar espaço. A seguir está o algoritmo completo.
Inserção
1) Inicialize x como root.
2) Enquanto x não for folha, faça o seguinte
... a) Encontre o filho de x que será percorrido a seguir. Deixe a criança ser y.
.. b) Se y não estiver cheio, mude x para apontar para y.
.. c) Se y estiver cheio, divida-o e altere x para apontar para uma das duas partes de y. Se k for menor que o meio em y, defina x como a primeira parte de y. Outra segunda parte de y. Quando dividimos y, movemos uma chave de y para seu pai x.
3) O loop na etapa 2 para quando x é folha. x deve ter espaço para 1 chave extra, pois estamos dividindo todos os nós antecipadamente. Portanto, basta inserir k a x.
Observe que o algoritmo segue o livro Cormen. Na verdade, é um algoritmo de inserção proativo onde antes de descer para um nó, nós o dividimos se estiver cheio. A vantagem de dividir antes é que nunca atravessamos um nó duas vezes. Se não dividirmos um nó antes de descer até ele e dividi-lo apenas se uma nova chave for inserida (reativa), podemos acabar percorrendo todos os nós novamente, da folha à raiz. Isso acontece nos casos em que todos os nós no caminho da raiz à folha estão cheios. Então, quando chegamos ao nó folha, nós o dividimos e movemos uma chave para cima. Mover uma chave para cima causará uma divisão no nó pai (porque o pai já estava cheio). Esse efeito em cascata nunca acontece neste algoritmo de inserção proativa. Há uma desvantagem dessa inserção proativa, porém, podemos fazer divisões desnecessárias.
Vamos entender o algoritmo com uma árvore de exemplo de grau mínimo 't' como 3 e uma sequência de inteiros 10, 20, 30, 40, 50, 60, 70, 80 e 90 em uma B-Tree inicialmente vazia.
Inicialmente, a raiz é NULL. Vamos primeiro inserir 10.

Vamos agora inserir 20, 30, 40 e 50. Todos eles serão inseridos na raiz porque o número máximo de chaves que um nó pode acomodar é 2 * t - 1, que é 5.

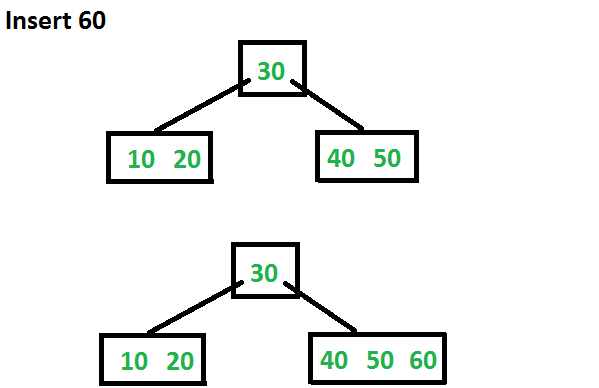
Vamos agora inserir 60. Como o nó raiz está cheio, ele primeiro será dividido em dois e, em seguida, 60 será inserido no filho apropriado.
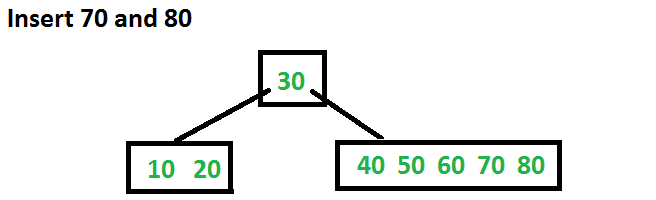
Vamos agora inserir 70 e 80. Essas novas chaves serão inseridas na folha apropriada sem qualquer divisão.
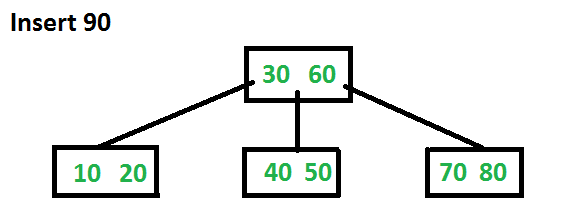
Vamos agora inserir 90. Esta inserção causará uma divisão. A chave do meio irá até o pai.
A seguir está a implementação em C++ do algoritmo proativo acima.
// C++ program for B-Tree insertion
#include<iostream>
using namespace std;
// A BTree node
class BTreeNode
{
int *keys; // An array of keys
int t; // Minimum degree (defines the range for number of keys)
BTreeNode **C; // An array of child pointers
int n; // Current number of keys
bool leaf; // Is true when node is leaf. Otherwise false
public:
BTreeNode(int _t, bool _leaf); // Constructor
// A utility function to insert a new key in the subtree rooted with
// this node. The assumption is, the node must be non-full when this
// function is called
void insertNonFull(int k);
// A utility function to split the child y of this node. i is index of y in
// child array C[]. The Child y must be full when this function is called
void splitChild(int i, BTreeNode *y);
// A function to traverse all nodes in a subtree rooted with this node
void traverse();
// A function to search a key in the subtree rooted with this node.
BTreeNode *search(int k); // returns NULL if k is not present.
// Make BTree friend of this so that we can access private members of this
// class in BTree functions
friend class BTree;
};
// A BTree
class BTree
{
BTreeNode *root; // Pointer to root node
int t; // Minimum degree
public:
// Constructor (Initializes tree as empty)
BTree(int _t)
{ root = NULL; t = _t; }
// function to traverse the tree
void traverse()
{ if (root != NULL) root->traverse(); }
// function to search a key in this tree
BTreeNode* search(int k)
{ return (root == NULL)? NULL : root->search(k); }
// The main function that inserts a new key in this B-Tree
void insert(int k);
};
// Constructor for BTreeNode class
BTreeNode::BTreeNode(int t1, bool leaf1)
{
// Copy the given minimum degree and leaf property
t = t1;
leaf = leaf1;
// Allocate memory for maximum number of possible keys
// and child pointers
keys = new int[2*t-1];
C = new BTreeNode *[2*t];
// Initialize the number of keys as 0
n = 0;
}
// Function to traverse all nodes in a subtree rooted with this node
void BTreeNode::traverse()
{
// There are n keys and n+1 children, traverse through n keys
// and first n children
int i;
for (i = 0; i < n; i++)
{
// If this is not leaf, then before printing key[i],
// traverse the subtree rooted with child C[i].
if (leaf == false)
C[i]->traverse();
cout << " " << keys[i];
}
// Print the subtree rooted with last child
if (leaf == false)
C[i]->traverse();
}
// Function to search key k in subtree rooted with this node
BTreeNode *BTreeNode::search(int k)
{
// Find the first key greater than or equal to k
int i = 0;
while (i < n && k > keys[i])
i++;
// If the found key is equal to k, return this node
if (keys[i] == k)
return this;
// If key is not found here and this is a leaf node
if (leaf == true)
return NULL;
// Go to the appropriate child
return C[i]->search(k);
}
// The main function that inserts a new key in this B-Tree
void BTree::insert(int k)
{
// If tree is empty
if (root == NULL)
{
// Allocate memory for root
root = new BTreeNode(t, true);
root->keys[0] = k; // Insert key
root->n = 1; // Update number of keys in root
}
else // If tree is not empty
{
// If root is full, then tree grows in height
if (root->n == 2*t-1)
{
// Allocate memory for new root
BTreeNode *s = new BTreeNode(t, false);
// Make old root as child of new root
s->C[0] = root;
// Split the old root and move 1 key to the new root
s->splitChild(0, root);
// New root has two children now. Decide which of the
// two children is going to have new key
int i = 0;
if (s->keys[0] < k)
i++;
s->C[i]->insertNonFull(k);
// Change root
root = s;
}
else // If root is not full, call insertNonFull for root
root->insertNonFull(k);
}
}
// A utility function to insert a new key in this node
// The assumption is, the node must be non-full when this
// function is called
void BTreeNode::insertNonFull(int k)
{
// Initialize index as index of rightmost element
int i = n-1;
// If this is a leaf node
if (leaf == true)
{
// The following loop does two things
// a) Finds the location of new key to be inserted
// b) Moves all greater keys to one place ahead
while (i >= 0 && keys[i] > k)
{
keys[i+1] = keys[i];
i--;
}
// Insert the new key at found location
keys[i+1] = k;
n = n+1;
}
else // If this node is not leaf
{
// Find the child which is going to have the new key
while (i >= 0 && keys[i] > k)
i--;
// See if the found child is full
if (C[i+1]->n == 2*t-1)
{
// If the child is full, then split it
splitChild(i+1, C[i+1]);
// After split, the middle key of C[i] goes up and
// C[i] is splitted into two. See which of the two
// is going to have the new key
if (keys[i+1] < k)
i++;
}
C[i+1]->insertNonFull(k);
}
}
// A utility function to split the child y of this node
// Note that y must be full when this function is called
void BTreeNode::splitChild(int i, BTreeNode *y)
{
// Create a new node which is going to store (t-1) keys
// of y
BTreeNode *z = new BTreeNode(y->t, y->leaf);
z->n = t - 1;
// Copy the last (t-1) keys of y to z
for (int j = 0; j < t-1; j++)
z->keys[j] = y->keys[j+t];
// Copy the last t children of y to z
if (y->leaf == false)
{
for (int j = 0; j < t; j++)
z->C[j] = y->C[j+t];
}
// Reduce the number of keys in y
y->n = t - 1;
// Since this node is going to have a new child,
// create space of new child
for (int j = n; j >= i+1; j--)
C[j+1] = C[j];
// Link the new child to this node
C[i+1] = z;
// A key of y will move to this node. Find the location of
// new key and move all greater keys one space ahead
for (int j = n-1; j >= i; j--)
keys[j+1] = keys[j];
// Copy the middle key of y to this node
keys[i] = y->keys[t-1];
// Increment count of keys in this node
n = n + 1;
}
// Driver program to test above functions
int main()
{
BTree t(3); // A B-Tree with minimum degree 3
t.insert(10);
t.insert(20);
t.insert(5);
t.insert(6);
t.insert(12);
t.insert(30);
t.insert(7);
t.insert(17);
cout << "Traversal of the constructed tree is ";
t.traverse();
int k = 6;
(t.search(k) != NULL)? cout << "\nPresent" : cout << "\nNot Present";
k = 15;
(t.search(k) != NULL)? cout << "\nPresent" : cout << "\nNot Present";
return 0;
}Saída:
Traversal of the constructed tree is 5 6 7 10 12 17 20 30 Present Not Present
Referências:
Introdução aos algoritmos 3ª edição por Clifford Stein, Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest
http://www.cs.utexas.edu/users/djimenez/utsa/cs3343/lecture17.html
Por favor, escreva comentários se você encontrar algo incorreto, ou se deseja compartilhar mais informações sobre o tópico discutido acima.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva