Intuição de SpanBert
Pré-requisito: Modelo BERT
SpanBERT vs BERT
O SpanBERT é uma melhoria no modelo BERT que fornece previsão aprimorada de extensões de texto. Ao contrário do BERT, realizamos as seguintes etapas aqui: i) mascarar spans contíguos aleatórios, em vez de tokens individuais aleatórios.
ii) treinar o modelo com base em tokens no início e no final do limite do intervalo (conhecido como Span Boundary Objective ) para prever todos os spans marcados.
Ele difere do modelo BERT em seu esquema de mascaramento, pois o BERT é usado para mascarar tokens aleatoriamente em uma sequência, mas aqui no SpanBERT nós mascaramos extensões contíguas aleatórias de texto.
Outra diferença é o objetivo do treinamento. O BERT foi treinado em dois objetivos (2 funções de perda):
- Modelagem de linguagem mascarada (MLM) - prevendo o token de máscara na saída
- Next Sequence Prediction (NSP) - Predição se 2 sequências de textos se seguiram.
Mas no SpanBERT , a única coisa em que o modelo é treinado é o objetivo de limite do span , que mais tarde contribui para a função de perda.
SpanBERT: Implementação
Para implementar o SpanBERT, construímos uma réplica do modelo BERT, mas fazemos certas alterações para que tenha um desempenho melhor do que o modelo BERT original. Observa-se que o modelo BERT tem um desempenho muito melhor quando treinado apenas em 'Modelagem de Linguagem Mascarada' do que em 'Previsão de Próxima Sequência'. Portanto, desconsideramos o NSP e ajustamos o modelo na linha de base de Sequência Única ao construir a réplica do modelo BERT, melhorando assim sua precisão de predição.
SpanBERT: Intuição
Fig 1: SpanBERT de treinamento
A Figura 1 mostra o treinamento do modelo SpanBERT. Na frase dada, a extensão das palavras ' um torneio de campeonato de futebol ' é mascarada. O Span Boundary objectivo é definida pela x 4 e x 9 em destaque na azul. Isso é usado para prever cada token na extensão mascarada.
Aqui na Fig. 1, uma sequência de palavras ' um torneio de campeonato de futebol ' é criada e toda a sequência é passada através do bloco codificador e obtém a previsão dos tokens mascarados como saída. (x 5 a x 8 )
Por exemplo, se tivéssemos que prever para o token x 6 (ou seja, futebol), abaixo está a perda equivalente (conforme mostrado na Eqn (1) ) que obteríamos.
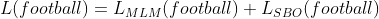
Eqn- (1)
Esta perda é a soma das perdas dadas pelas perdas de MLM e SBO.
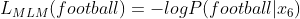
Eqn- (2)
Agora, a perda de MLM é o mesmo que '-ve log da probabilidade' ou, em termos mais simples, quais são as chances de x 6 ser futebol.
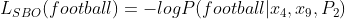
Eqn- (3)
Then, the SBO loss is depends on three parameters. x4 - the start of the span boundary x6 - the end of the span boundary P2 - the position of x6 (football) from the starting point (x4) So given these three parameters, we see how good the model is at predicting the token 'football'.
Usando as duas funções de perda acima, o modelo BERT é ajustado e é denominado SpanBERT.
Objetivo de limite de amplitude:
Aqui, obtemos a saída como um vetor que codifica os tokens na sequência representada como ( x 1 ,… .., x n ). O intervalo mascarado de tokens é representado por ( x s ,…., X e ), onde x s denota o início e x e denota o fim do intervalo mascarado de tokens. A função SBO é representada como:
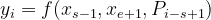
Eqn- (4)
where P1, P2, ... are relative positions w.r.t the left boundary token xs-1.
A função SBO ' f' é uma rede feed-forward de 2 camadas com ativação GeLU . Esta rede de 2 camadas é representada como:
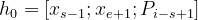
Eqn- (5)
where, h0 = first hidden representation xs-1 = starting boundary word xe+1 = ending boundary word Pi-s+1 = positional embedding of the word
Passamos h 0 para a primeira camada oculta com peso W 1 .
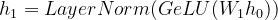
Eqn- (6)
where, GeLU (Gaussian Error Linear Units) = non-linear activation function h1 = second hidden representation W1 = weight of first hidden layer LayerNorm = a normalization technique used to prevent interactions within the batches
Agora, passamos isso por outra camada com peso W 2 para obter a saída y i .
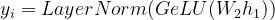
Eqn- (7)
where, yi = vector representation for all the toxens xi W2 = weight of second hidden layer
Para generalizar, a perda equivalente do SpanBERT de um token específico em um intervalo de palavras é calculada por:
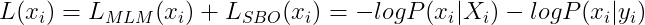
Eqn- (8)
where, Xi = final representation of tokens xi = original sequence of tokens yi = output obtained by passing xi through 2-layer feed forward network.
Esta foi uma intuição e compreensão básicas do modelo SpanBERT e como ele prevê um intervalo de palavras em vez do token individual, tornando-o mais poderoso do que o modelo BERT. Para qualquer dúvida / consulta, comente abaixo.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva