Previsão da direção do preço das ações usando máquinas de vetores de suporte
Vamos implementar um projeto End-to-End usando Support Vector Machines para viver o comércio para nós. Você provavelmente deve ter ouvido falar do termo mercado de ações, que é conhecido por ter feito a vida de milhares e ter destruído a vida de milhões. Se você não está familiarizado com o mercado de ações, pode navegar em algumas coisas básicas sobre os mercados.
Ferramentas e tecnologias utilizadas:
- Python
- Sklearn- Classificador de vetores de suporte
- Yahoo Finance
- Jupyter-Notebook
- Turno azul
Implementação passo a passo
Etapa 1: importar as bibliotecas
# Machine learning
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# For data manipulation
import pandas as pd
import numpy as np
# To plot
import matplotlib.pyplot as plt
plt.style.use('seaborn-darkgrid')
# To ignore warnings
import warnings
warnings.filterwarnings("ignore")Etapa 2: ler os dados do estoque
Leremos os dados de estoque baixados do site de finanças do Yahoo. Os dados são armazenados no formato OHLC (aberto, alto, baixo, fechado) em um arquivo CSV. Para ler um arquivo CSV, você pode usar o método read_csv() do pandas.
Sintaxe:
pd.read_csv(filename, index_col)
Observação: baixamos os dados do último ano de Reliance Industries Trading In NSE do site de finanças do Yahoo.
Arquivo usado:
# Read the csv file using read_csv
# method of pandas
df = pd.read_csv('RELIANCE.csv')
dfSaída:
Etapa 3: preparação de dados
Os dados precisavam ser processados antes do uso, de modo que a coluna de data deveria atuar como um índice para fazer isso
# Changes The Date column as index columns
df.index = pd.to_datetime(df['Date'])
df
# drop The original date column
df = df.drop(['Date'], axis='columns')
dfSaída:
Etapa 4: definir as variáveis explicativas
Variáveis explicativas ou independentes são usadas para prever o valor da variável de resposta. O X é um conjunto de dados que contém as variáveis que são usadas para a previsão. OX consiste em variáveis como 'Abrir - Fechar' e 'Alto - Baixo'. Eles podem ser entendidos como indicadores com base nos quais o algoritmo irá prever a tendência de amanhã. Sinta-se à vontade para adicionar mais indicadores e ver o desempenho
# Create predictor variables
df['Open-Close'] = df.Open - df.Close
df['High-Low'] = df.High - df.Low
# Store all predictor variables in a variable X
X = df[['Open-Close', 'High-Low']]
X.head()Saída:
Etapa 5: definir a variável de destino
A variável de destino é o resultado que o modelo de aprendizado de máquina irá prever com base nas variáveis explicativas. y é um conjunto de dados de destino que armazena o sinal de negociação correto que o algoritmo de aprendizado de máquina tentará prever. Se o preço de amanhã for maior do que o preço de hoje, compraremos a ação específica, caso contrário não teremos posição na. Armazenaremos +1 para um sinal de compra e 0 para nenhuma posição em y. Usaremos a função where() do NumPy para fazer isso.
Sintaxe:
np.where(condition,value_if_true,value_if_false)
# Target variables
y = np.where(df['Close'].shift(-1) > df['Close'], 1, 0)
ySaída:

Etapa 6: dividir os dados em treinar e testar
Vamos dividir os dados em conjuntos de dados de treinamento e teste. Isso é feito para que possamos avaliar a eficácia do modelo no conjunto de dados de teste
split_percentage = 0.8
split = int(split_percentage*len(df))
# Train data set
X_train = X[:split]
y_train = y[:split]
# Test data set
X_test = X[split:]
y_test = y[split:]Etapa 7: Classificador de vetores de suporte (SVC)
Usaremos a função SVC() da biblioteca sklearn.svm.SVC para criar nosso modelo de classificador usando o método fit() no conjunto de dados de treinamento.
# Support vector classifier
cls = SVC().fit(X_train, y_train)Etapa 8: precisão do classificador
Vamos calcular a precisão do algoritmo no trem e testar o conjunto de dados comparando os valores reais do sinal com os valores previstos do sinal. A função precision_score() será usada para calcular a precisão.

Uma precisão de 50% + nos dados de teste sugere que o modelo do classificador é eficaz.
Etapa 9: Implementação da estratégia
Vamos prever o sinal (comprar ou vender) usando a função cls.predict().
df['Predicted_Signal'] = cls.predict(X)Calcular retornos diários
# Calculate daily returns
df['Return'] = df.Close.pct_change()Calcular retornos de estratégia
# Calculate strategy returns
df['Strategy_Return'] = df.Return *df.Predicted_Signal.shift(1)Calcular retornos cumulativos
# Calculate Cumulutive returns
df['Cum_Ret'] = df['Return'].cumsum()
dfCalcular os retornos cumulativos da estratégia
# Plot Strategy Cumulative returns
df['Cum_Strategy'] = df['Strategy_Return'].cumsum()
dfTraçar os retornos da estratégia versus os retornos originais
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(Df['Cum_Ret'],color='red')
plt.plot(Df['Cum_Strategy'],color='blue')Saída:
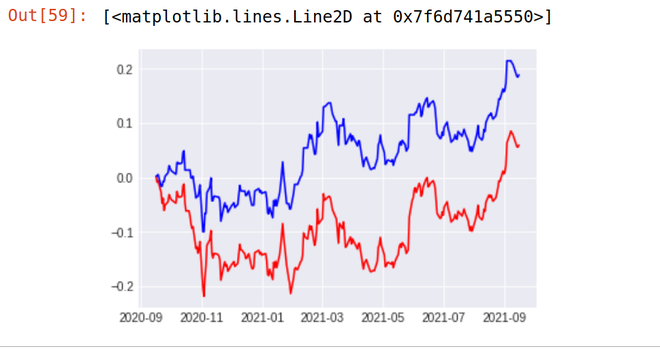
Como você pode ver, nossa estratégia parece estar superando totalmente o desempenho das ações da Reliance. Nossa Estratégia (Linha Azul) Proporcionou retorno de 18,87% no último 1 ano enquanto o estoque da Reliance Industries (Linha Vermelha) Proporcionou Retorno de apenas 5,97% no último 1 ano.
Resultado do back-teste
1. TCS
Stock Return Over Last 1 year - 48% Strategy result - 48.9 %
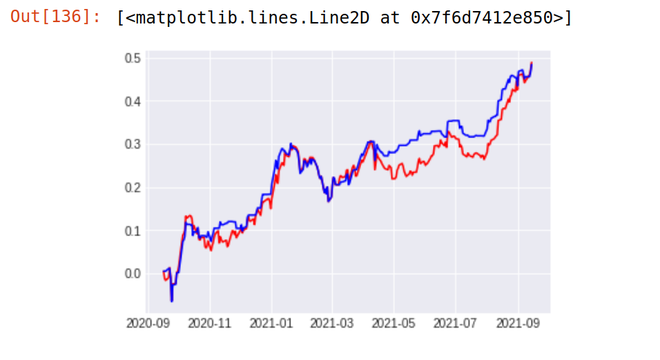
2. BANCO ICICI
Stock Return Over Last 1 year - 48% Strategy result - 48.9 %
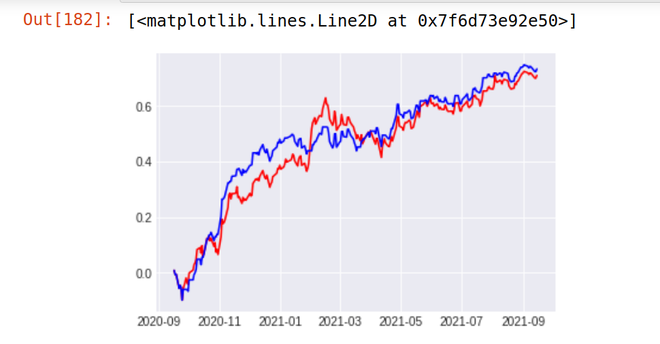
Implantando estratégia para viver o mercado
A estratégia codificada pode ser facilmente implementada no mercado ao vivo e também pode ser testada em qualquer número de dados durante as trocas. A implantação pode ser feita facilmente usando a plataforma BlueShift. É uma plataforma interativa com Live Data Feed e conexões por meio de vários Brokers. Você pode fazer back-teste na plataforma BlueShift por qualquer número de tempo com dados de várias bolsas.
Conclusão
- O provedor de estratégia retornos promissores durante o mercado ao vivo. Atualmente, acabei de treinar o modelo com base nos níveis do dia anterior. No entanto, para aumentar a precisão do modelo, também adicionamos vários indicadores técnicos para treinar o modelo, como RSI, ADX, ATR, MACD, estocástico e muitos mais.
- Para obter mais precisão no mercado ao vivo O aprendizado profundo provou ser muito eficaz na negociação em um mercado ao vivo. Podemos automatizar nossas negociações usando Reinforcement Learning e também usando Stacked LSTM que dá um aumento exponencial para nossos retornos de estratégia.
Nota: O dinheiro real não deve ser implantado até a conclusão do Backtesting da estratégia e sem retornos promissores da estratégia durante a negociação de papel
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva