Previsão do índice de qualidade do ar usando Python
Vamos ver como prever o índice de qualidade do ar usando Python. O AQI é calculado com base na quantidade de poluentes químicos. Usando o aprendizado de máquina, podemos prever o AQI.
AQI: O índice de qualidade do ar é um índice para relatar a qualidade do ar diariamente. Em outras palavras, é uma medida de como a poluição do ar afeta a saúde de uma pessoa em um curto período de tempo. O AQI é calculado com base na concentração média de um determinado poluente medido em um intervalo de tempo padrão. Geralmente, o intervalo de tempo é de 24 horas para a maioria dos poluentes, 8 horas para monóxido de carbono e ozônio.
Podemos ver como a poluição do ar está olhando para o AQI
| Nível AQI | Alcance AQI |
| Boa | 0 - 50 |
| Moderado | 51 - 100 |
| Pouco saudável | 101 - 150 |
| Insalubre para pessoas fortes | 151 - 200 |
| Perigoso | 201+ |
Vamos encontrar o AQI baseado em poluentes químicos usando o conceito de aprendizado de máquina.
Nota: Para baixar o conjunto de dados clique aqui .
Descrição do conjunto de dados
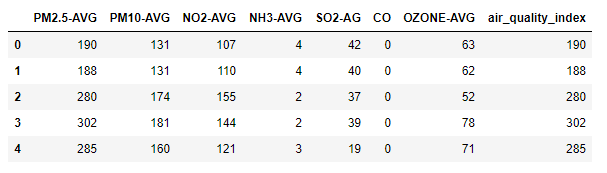
Ele contém 8 atributos, dos quais 7 são quantidades de poluição química e um é Índice de Qualidade do Ar. PM2.5-AVG, PM10-AVG, NO2-AVG, NH3-AVG, SO2-AG, OZONE-AVG são atributos independentes. air_quality_index é um atributo dependente. Já air_quality_index é calculado com base nos 7 atributos.
Como os dados são numéricos e não há valores ausentes nos dados, nenhum pré-processamento é necessário. Nosso objetivo é prever o AQI, então essa tarefa é Classificação ou regressão. Portanto, como nosso rótulo de classe é contínuo, a técnica de regressão é necessária.
A regressão é uma técnica de aprendizado supervisionado que se ajusta aos dados em um determinado intervalo. Exemplo de técnicas de regressão em Python:
- Random Forest Regressor
- Ada Boost Regressor
- Bagging Regressor
- Regressão Linear etc.
# importing pandas module for data frame
import pandas as pd
# loading dataset and storing in train variable
train=pd.read_csv('AQI.csv')
# display top 5 data
train.head()Saída:
# importing Randomforest
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import RandomForestRegressor
# creating model
m1 = RandomForestRegressor()
# separating class label and other attributes
train1 = train.drop(['air_quality_index'], axis=1)
target = train['air_quality_index']
# Fitting the model
m1.fit(train1, target)
'''RandomForestRegressor(bootstrap=True, ccp_alpha=0.0, criterion='mse',
max_depth=None, max_features='auto', max_leaf_nodes=None,
max_samples=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=100, n_jobs=None, oob_score=False,
random_state=None, verbose=0, warm_start=False)'''
# calculating the score and the score is 97.96360799890066%
m1.score(train1, target) * 100
# predicting the model with other values (testing the data)
# so AQI is 123.71
m1.predict([[123, 45, 67, 34, 5, 0, 23]])
# Adaboost model
# importing module
# defining model
m2 = AdaBoostRegressor()
# Fitting the model
m2.fit(train1, target)
'''AdaBoostRegressor(base_estimator=None, learning_rate=1.0, loss='linear',
n_estimators=50, random_state=None)'''
# calculating the score and the score is 96.15377360010211%
m2.score(train1, target)*100
# predicting the model with other values (testing the data)
# so AQI is 94.42105263
m2.predict([[123, 45, 67, 34, 5, 0, 23]])
Saída:
Por isso, podemos dizer que, por dados de teste fornecidos, obtivemos 123 e 95, portanto, o AQI não é saudável.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva