Python | Pandas Dataframe.rank()
Python é uma ótima linguagem para fazer análise de dados, principalmente por causa do fantástico ecossistema de pacotes python centrados em dados. O Pandas é um desses pacotes e torna a importação e análise de dados muito mais fácil.
O Dataframe.rank()método Pandas retorna uma classificação de cada índice respectivo de uma série passada. A classificação é retornada com base na posição após a classificação.
Syntax:
DataFrame.rank (axis = 0, method = 'average', numeric_only = None, na_option = 'keep', ascending = True, pct = False)
Parameters:
eixo: 0 ou 'índice' para linhas e 1 ou 'colunas' para coluna.
método: Recebe uma string de entrada ('média', 'min', 'max', 'primeiro', 'denso') que diz aos pandas o que fazer com os mesmos valores. O padrão é a média, o que significa atribuir a média das classificações aos valores semelhantes.
numeric_only: recebe um valor booleano e a função de classificação funciona em valores não numéricos apenas se for False.
na_option: Recebe 3 string de entrada ('keep', 'top', 'bottom') para definir a posição dos valores nulos se houver algum na série passada.
ascendente: valor booleano classificado em ordem ascendente se for verdadeiro.
pct: valor booleano classificado em porcentagem, se True.
Return type:Série com classificação de cada índice de série do chamador.
Para obter o link para o arquivo CSV usado no código, clique aqui.
Exemplo nº 1: Coluna de classificação com valores únicos
No exemplo a seguir, uma nova coluna de classificação é criada, classificando o Nome de cada Jogador. Todos os valores na coluna Nome são únicos e, portanto, não há necessidade de descrever um método.
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# creating a rank column and passing the returned rank series
data["Rank"] = data["Name"].rank()
# display
data
# sorting w.r.t name column
data.sort_values("Name", inplace = True)
# display after sorting w.r.t Name column
dataSaída:
conforme mostrado na imagem, uma classificação de coluna foi criada com a classificação de cada Nome. Depois que a função sort_value classificou o quadro de dados em relação ao nome, pode-se ver que a classificação também foi classificada, uma vez que eram apenas classificações de nomes.
Antes de classificar - 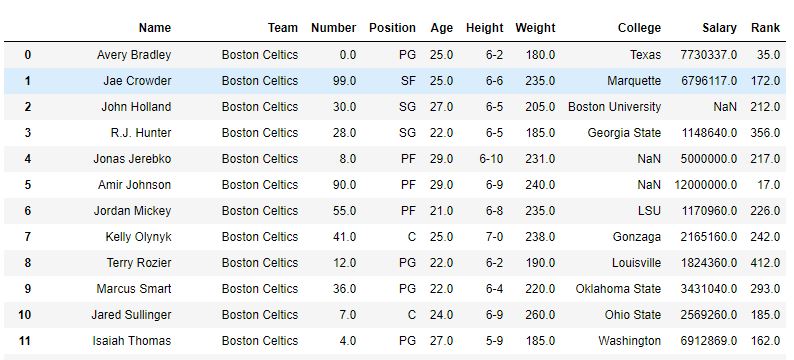
Depois de classificar - 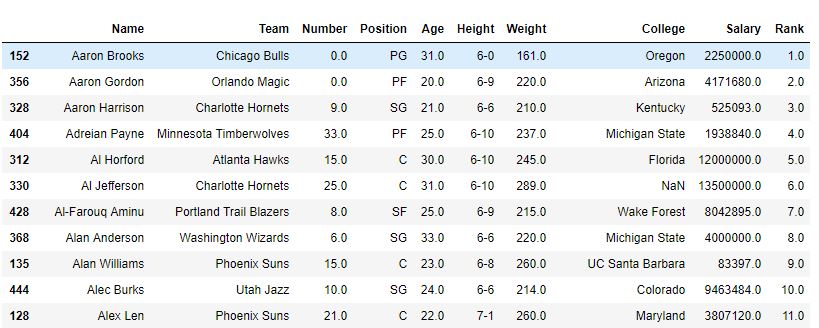
Exemplo # 2: Classificar coluna com alguns valores semelhantes
No exemplo a seguir, o quadro de dados é classificado primeiro em relação ao nome da equipe e, primeiro, o método é o padrão (ou seja, média) e, portanto, a classificação dos mesmos jogadores da equipe é a média. Depois disso, o método min também é usado para ver a saída.
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# sorting w.r.t team name
data.sort_values("Team", inplace = True)
# creating a rank column and passing the returned rank series
# change method to 'min' to rank by minimum
data["Rank"] = data["Team"].rank(method ='average')
# display
dataSaída:
Com método = 'média'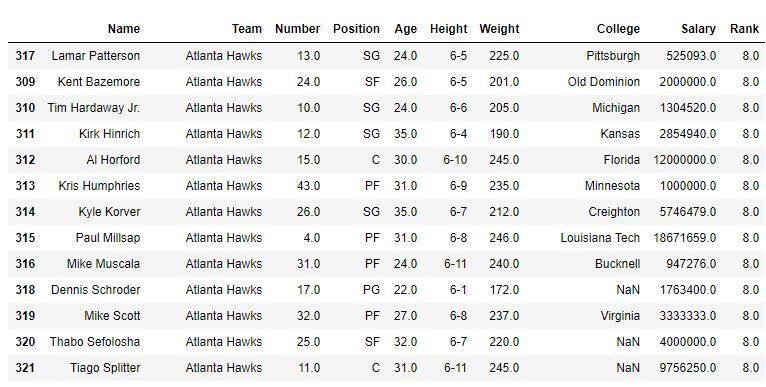
Com método = 'min'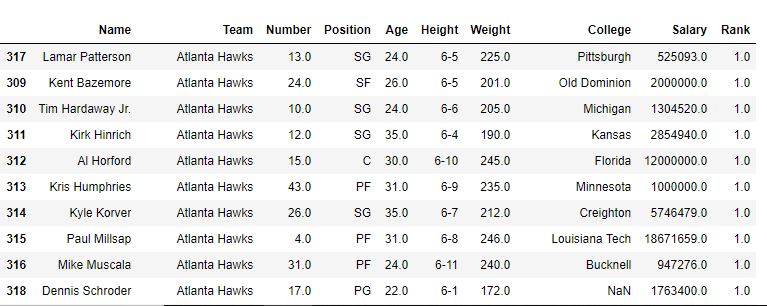
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva