Python - Subconjunto de DataFrame por nome de coluna
Usando a biblioteca Pandas, podemos realizar várias operações em um DataFrame. Podemos até criar e acessar o subconjunto de um DataFrame em vários formatos. A tarefa aqui é criar um subconjunto DataFrame por nome de coluna. Podemos escolher diferentes métodos para realizar esta tarefa. Aqui estão os métodos possíveis mencionados abaixo -
Antes de realizar qualquer ação, precisamos escrever algumas linhas de código para importar as bibliotecas necessárias e criar um DataFrame.
Criação do DataFrame
#import pandas
import pandas as pd
# create dataframe
data = {'Name': ['John', 'Emily', 'Lara', 'Lucas', 'Katy', 'Jordan'],
'Gender': [30, 27, 21, 21, 16, 20],
'Branch': ['Arts', 'Arts', 'Commerce', 'Science',
'Science', 'Science'],
'pre_1': [9, 9, 10, 7, 6, 9],
'pre_2': [8, 7, 10, 6, 8, 8]}
df = pd.DataFrame(data)
dfSaída:
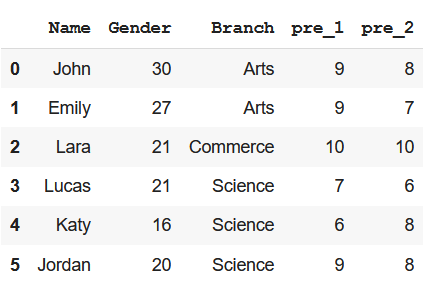
: Método 1 Usando Python iLOC() função
Esta função nos permite criar um subconjunto escolhendo valores específicos de colunas com base em índices.
Sintaxe:
df_name.iloc[beg_index:end_index+1,beg_index:end_index+1]
Exemplo: crie um subconjunto com as colunas Nome, Sexo e Ramo
# create a subset of all rows
# and Name, Gender and Branch column
df.iloc[:, 0:3]Saída :
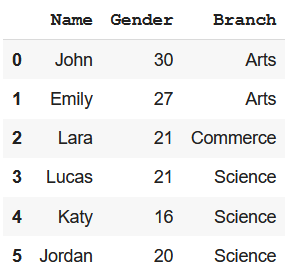
Método 2: usando o operador de indexação
Podemos usar o operador de indexação, ou seja, colchetes para criar um subconjunto de dataframe
Exemplo: crie um subconjunto com as colunas Name, pre_1 e pre_2
# creating subset dataframe using
# indexing operator
df[['Name', 'pre_1', 'pre_2']]Saída -
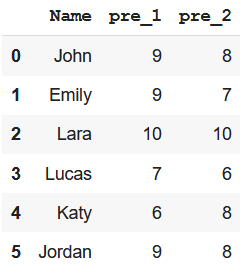
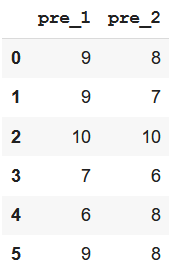
Método 3: usando o método filter() com palavra-chave semelhante
Podemos usar esse método particularmente quando precisamos criar um subconjunto de dataframe com colunas com nomes padronizados de forma semelhante.
Exemplo: crie um subconjunto com as colunas pre_1 e pre_2
# create a subset of columns pre_1 and pre_2
# using filter() method
df.filter(like='pre')Saída:
Atenção geek! Fortaleça suas bases com o Python Programming Foundation Course e aprenda o básico.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva