Python - Teste de Correlação de Pearson entre Duas Variáveis
O que é teste de correlação?
A força da associação entre duas variáveis é conhecida como teste de correlação.
Por exemplo, se estamos interessados em saber se existe uma relação entre as alturas dos pais e dos filhos, um coeficiente de correlação pode ser calculado para responder a esta pergunta.
Para saber mais sobre correlação, consulte isto.
Métodos para análises de correlação:
- Correlação paramétrica: mede uma dependência linear entre duas variáveis (xey), é conhecido como teste de correlação paramétrica porque depende da distribuição dos dados.
- Correlação não paramétrica: Kendall (tau) e Spearman (rho) , que são coeficientes de correlação baseados em classificação, são conhecidos como correlação não paramétrica.
Observação: o método mais comumente usado é o método de correlação paramétrica.
Fórmula de correlação de Pearson:
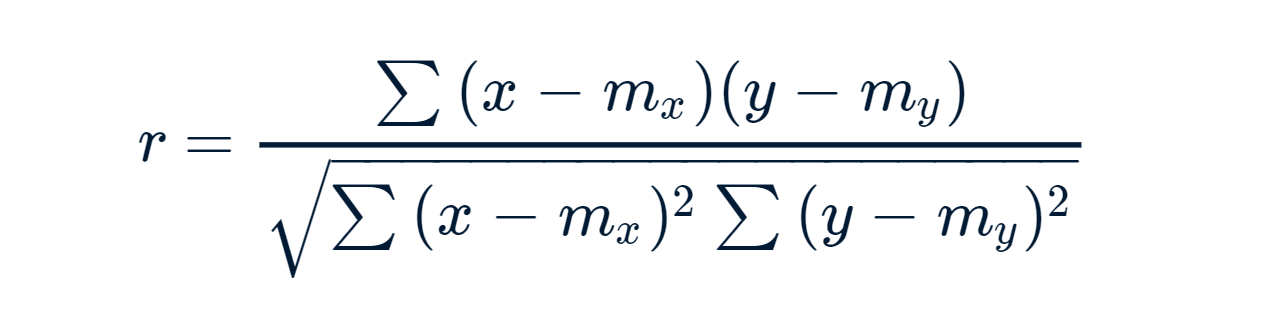
x e y são dois vetores de comprimento n
m, x e m, y correspondem às médias de x e y, respectivamente.
Nota:
- r assume um valor entre -1 (correlação negativa) e 1 (correlação positiva).
- r = 0 significa nenhuma correlação.
- Não pode ser aplicado a variáveis ordinais.
- O tamanho da amostra deve ser moderado (20-30) para uma boa estimativa.
- Valores discrepantes podem levar a valores enganosos, meios não robustos com valores discrepantes.
Para calcular a correlação de Pearson em Python - a função pearsonr() pode ser usada.
Funções Python
Sintaxe:
pearsonr (x, y)Parâmetros:
x, y: vetores numéricos com o mesmo comprimento
Dados: Baixe o arquivo csv aqui.
Código: código Python para encontrar a correlação de Pearson
importpandas as pdfromscipy.statsimportpearsonrdf=pd.read_csv("Auto.csv")list1=df['weight']list2=df['mpg']corr, _=pearsonr(list1, list2)('Pearsons correlation: %.3f'%corr)
Resultado:
A correlação de Pearson é: -0,878
Correlação de Pearson para os dados de
Anscombe : os dados de Anscombe, também conhecidos como quarteto de Anscombe, são compostos por quatro conjuntos de dados que têm propriedades estatísticas simples quase idênticas, mas parecem muito diferentes quando representados graficamente. Cada conjunto de dados consiste em onze (x, y) pontos. Eles foram construídos em 1973 pelo estatístico Francis Anscombe para demonstrar a importância dos dados gráficos antes de analisá-los e o efeito de outliers nas propriedades estatísticas.
Esses 4 conjuntos de 11 pontos de dados são fornecidos aqui. Faça download do arquivo csv aqui.
Quando plotamos esses pontos, fica assim. Estou considerando 3 conjuntos de 11 pontos de dados aqui.
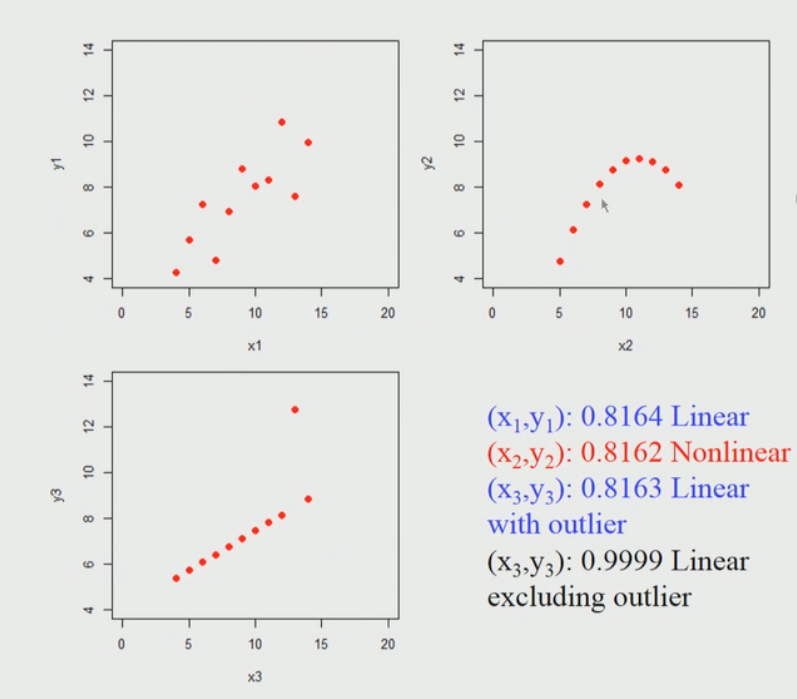
Breve explicação do diagrama acima:
Então, se aplicarmos o coeficiente de correlação de Pearson para cada um desses conjuntos de dados, descobriremos que é quase idêntico, não importa se você realmente aplica em um primeiro conjunto de dados (canto superior esquerdo) ou segundo conjunto de dados (canto superior direito) ou o terceiro conjunto de dados (canto inferior esquerdo).
Portanto, o que parece indicar é que, se aplicarmos a correlação de Pearson, encontraremos o coeficiente de correlação alto próximo a um neste primeiro caso de conjunto de dados (canto superior esquerdo). O ponto principal é que não podemos concluir imediatamente que, se o coeficiente de correlação de Pearson for alto, então há uma relação linear entre eles, por exemplo, no segundo conjunto de dados (canto superior direito), esta é uma relação não linear e ainda dá origem a um valor alto.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva