Reconhecimento de fala em Python usando Google Speech API
O reconhecimento de fala é um recurso importante em diversos aplicativos utilizados, como automação residencial, inteligência artificial, etc. Este artigo tem como objetivo fornecer uma introdução sobre como utilizar a biblioteca SpeechRecognition do Python. Isso é útil porque pode ser usado em microcontroladores como o Raspberri Pis com a ajuda de um microfone externo.
Instalações Requeridas
O seguinte deve ser instalado:
- Módulo Python Speech Recognition:
sudo pip install SpeechRecognition
- PyAudio: Use o seguinte comando para usuários Linux
sudo apt-get install python-pyaudio python3-pyaudio
Se as versões nos repositórios forem muito antigas, instale o pyaudio usando o seguinte comando
sudo apt-get install portaudio19-dev python-all-dev python3-all-dev && sudo pip install pyaudio
Use pip3 em vez de pip para python3.
Os usuários do Windows podem instalar o pyaudio executando o seguinte comando em um terminal
pip instalar pyaudio
Entrada de fala usando um microfone e tradução de fala para texto
-
Configurar microfone (para microfones externos): É aconselhável especificar o microfone durante o programa para evitar falhas.
Digite lsusb no terminal. Uma lista de dispositivos conectados será exibida. O nome do microfone ficaria assimDispositivo USB 0x46d: 0x825: Áudio (hw: 1, 0)
Anote isso, pois ele será usado no programa.
- Definir tamanho do bloco: Basicamente, envolve a especificação de quantos bytes de dados queremos ler de uma vez. Normalmente, este valor é especificado em potências de 2, como 1024 ou 2048
- Definir taxa de amostragem: a taxa de amostragem define com que frequência os valores são registrados para processamento
- Defina a ID do dispositivo para o microfone selecionado : nesta etapa, especificamos a ID do dispositivo do microfone que desejamos usar para evitar ambigüidade no caso de haver vários microfones. Isso também ajuda a depurar, no sentido de que, durante a execução do programa, saberemos se o microfone especificado está sendo reconhecido. Durante o programa, especificamos um parâmetro device_id. O programa dirá que device_id não pôde ser encontrado se o microfone não for reconhecido.
- Permitir ajuste para ruído ambiente: Como o ruído ambiente varia, devemos permitir que o programa um segundo ou mais para ajustar o limite de energia da gravação para que seja ajustado de acordo com o nível de ruído externo.
- Tradução de voz para texto: isso é feito com a ajuda do Google Speech Recognition. Isso requer uma conexão ativa com a Internet para funcionar. No entanto, existem certos sistemas de reconhecimento offline, como o PocketSphinx, mas têm um processo de instalação muito rigoroso que requer várias dependências. O reconhecimento de voz do Google é um dos mais fáceis de usar.
As etapas acima foram implementadas abaixo:
editar
fechar
play_arrow
link
brilho_4
código
import speech_recognition as sr mic_name = "USB Device 0x46d:0x825: Audio (hw:1, 0)"sample_rate = 48000chunk_size = 2048r = sr.Recognizer() mic_list = sr.Microphone.list_microphone_names() for i, microphone_name in enumerate(mic_list): if microphone_name == mic_name: device_id = i with sr.Microphone(device_index = device_id, sample_rate = sample_rate, chunk_size = chunk_size) as source: r.adjust_for_ambient_noise(source) print "Say Something"audio = r.listen(source) try: text = r.recognize_google(audio) print "you said: " + text except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Google Speech Recognition service; {0}".format(e)) |
Transcrever um arquivo de áudio para texto
Se temos um arquivo de áudio que queremos traduzir em texto, simplesmente temos que substituir a fonte pelo arquivo de áudio em vez de um microfone.
Coloque o arquivo de áudio e o programa na mesma pasta para sua conveniência. Isso funciona para arquivos WAV, AIFF ou FLAC.
Uma implementação foi mostrada abaixo
editar
fechar
play_arrow
link
brilho_4
código
import speech_recognition as sr AUDIO_FILE = ("example.wav") r = sr.Recognizer() with sr.AudioFile(AUDIO_FILE) as source: audio = r.record(source) try: print("The audio file contains: " + r.recognize_google(audio)) except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Google Speech Recognition service; {0}".format(e)) |
Solução de problemas
Os seguintes problemas são comumente encontrados
- Microfone sem som: Isso faz com que a entrada não seja recebida. Para verificar isso, você pode usar o alsamixer.
Pode ser instalado usando
sudo apt-get install libasound2 alsa-utils alsa-oss
Digite amixer . O resultado será mais ou menos assim
Controle de mixer simples 'Master', 0 Capacidades: pvolume pswitch pswitch-join Canais de reprodução: Front Left - Front Right Limites: Reprodução 0 - 65536 Mono: Front Left: Playback 41855 [64%] [on] Frontal direita: Reprodução 65536 [100%] [on] Controle de mixer simples 'Capture', 0 Capacidades: cvolume cswitch cswitch-join Canais de captura: Front Left - Front Right Limites: Captura 0 - 65536 Front Left: Capture 0 [0%] [off] #witched off Frontal direita: Captura 0 [0%] [desligado]
Como você pode ver, o dispositivo de captura está desligado no momento. Para ligá-lo, digite alsamixer
Como você pode ver na primeira foto, ele está exibindo nossos dispositivos de reprodução. Pressione F4 para alternar para dispositivos de captura.
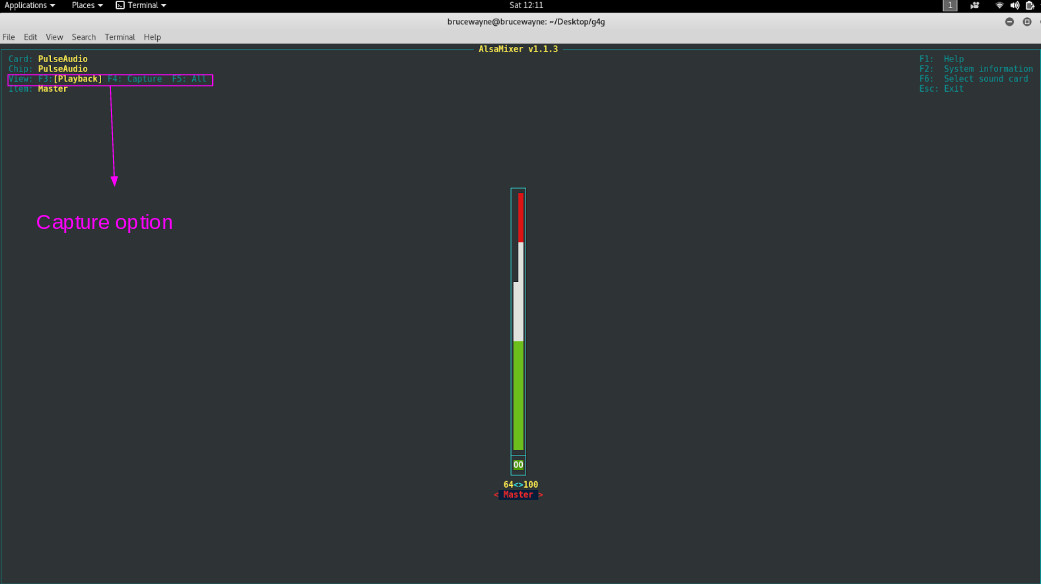
Na segunda imagem, a parte destacada mostra que o dispositivo de captura está sem som. Para reativar o som, pressione a barra de espaço

Como você pode ver na última foto, a parte destacada confirma que o dispositivo de captura não está mudo.

- Microfone atual não selecionado como dispositivo de captura:
Neste caso, o microfone pode ser configurado digitando alsamixer e selecionando placas de som. Aqui, você pode selecionar o dispositivo de microfone padrão.
Conforme mostrado na imagem, a parte destacada é onde você deve selecionar a placa de som.

A segunda imagem mostra a seleção de tela para placa de som

- Sem conexão com a Internet: a conversão de voz em texto requer uma conexão ativa com a Internet.
Este artigo é uma contribuição de Deepak Srivatsav . Se você gosta de GeeksforGeeks e gostaria de contribuir, você também pode escrever um artigo usando contribute.geeksforgeeks.org ou enviar o seu artigo para contribute@geeksforgeeks.org. Veja o seu artigo que aparece na página principal do GeeksforGeeks e ajude outros Geeks.
Escreva comentários se encontrar algo incorreto ou se quiser compartilhar mais informações sobre o tópico discutido acima.

As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva