Usando o módulo csv para ler os dados no Pandas
O formato denominado CSV (Comma Separated Values) é o formato mais comum de importação e exportação para planilhas e bancos de dados. Existiam vários formatos de CSV até sua padronização. A falta de um padrão bem definido significa que muitas vezes existem diferenças sutis nos dados produzidos e consumidos por diferentes aplicativos. Essas diferenças podem tornar irritante processar arquivos CSV de várias fontes. Para isso, usaremos a csvbiblioteca Python para ler e escrever dados tabulares no formato CSV.
Para obter o link para o arquivo CSV usado no código, clique aqui .
Código # 1: usaremos a csv.DictReader()função para importar o arquivo de dados para o ambiente do Python.
importcsvwithopen('auto-mpg.csv') as csvfile:mpg_data=list(csv.DictReader(csvfile))(mpg_data[:3])
Saída:
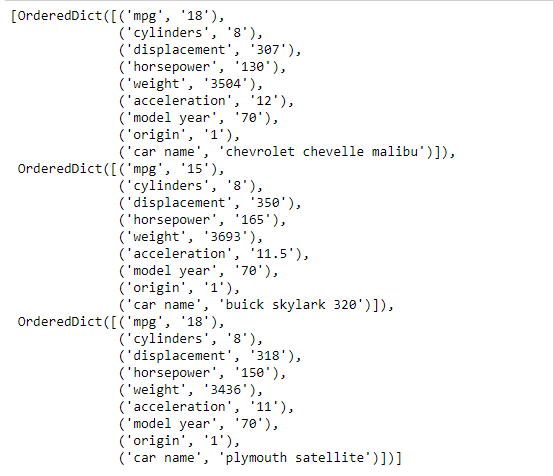
Como podemos ver, os dados são armazenados como uma lista de dicionário ordenado. Vamos realizar algumas operações nos dados para melhor compreensão.
Código # 2:
(mpg_data[0].keys)unique_cyl=set(data['cylinders']fordatainmpg_data)(unique_cyl)
Saída:
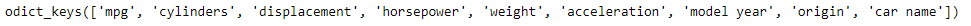
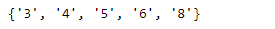
como podemos ver na saída, temos 5 valores únicos de cilindros em nosso conjunto de dados.
Código # 3: Agora vamos descobrir o valor do mpg médio para cada valor dos cilindros.
avg_mpg=[]forcinunique_cyl:mpgbycyl=0cylcount=0forxinmpg_data:ifx['cylinders']==c:mpgbycyl+=float(x['mpg'])cylcount+=1avg=mpgbycyl/cylcountavg_mpg.append((c, avg))avg_mpg.sort(key=lambdax : x[0])(avg_mpg)
Resultado :
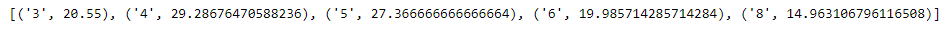
Como podemos ver na saída, o programa retornou com sucesso uma lista de tuplas contendo o mpg médio para cada tipo de cilindro exclusivo em nosso conjunto de dados.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva