Visualização de dados em Python usando Matplotlib e Seaborn
Às vezes, pode parecer mais fácil analisar um conjunto de pontos de dados e construir insights a partir dele, mas geralmente esse processo pode não produzir bons resultados. Pode haver muitas coisas não descobertas como resultado desse processo. Além disso, a maioria dos conjuntos de dados usados na vida real são muito grandes para fazer qualquer análise manualmente. É essencialmente aqui que a visualização de dados entra.
A visualização de dados é uma forma mais fácil de apresentar os dados, por mais complexos que sejam, para analisar tendências e relações entre variáveis com a ajuda de representação pictórica.
A seguir estão as vantagens da visualização de dados
- Representação mais fácil de dados obrigatórios
- Destaca áreas de bom e mau desempenho
- Explora a relação entre os pontos de dados
- Identifica padrões de dados, mesmo para pontos de dados maiores
Ao construir a visualização, é sempre uma boa prática manter alguns pontos mencionados abaixo em mente
- Garanta o uso apropriado de formas, cores e tamanho ao construir a visualização
- Plotagens / gráficos usando um sistema de coordenadas são mais pronunciados
- O conhecimento do gráfico adequado com relação aos tipos de dados traz mais clareza às informações
- O uso de rótulos, títulos, legendas e indicações passa informações ininterruptas para um público mais amplo
Bibliotecas Python
Existem várias bibliotecas python que podem ser usadas para construir visualizações como matplotlib, vispy, bokeh, seaborn, pygal, folium, plotly, abotoaduras e networkx . Dos muitos, matplotlib e seaborn parecem ser amplamente usados para o nível básico ao intermediário de visualizações.
Matplotlib
É uma biblioteca de visualização incrível em Python para gráficos 2D de arrays. É uma biblioteca de visualização de dados multiplataforma construída em arrays NumPy e projetada para trabalhar com a pilha SciPy mais ampla . Foi introduzido por John Hunter no ano de 2002. Vamos tentar entender alguns dos benefícios e recursos do matplotlib
- É rápido, eficiente, pois é baseado em numpy e também mais fácil de construir
- Passou por muitas melhorias da comunidade de código aberto desde o início e, portanto, uma biblioteca melhor com recursos avançados também
- Uma saída de visualização bem mantida com gráficos de alta qualidade atrai muitos usuários
- Gráficos básicos e avançados podem ser facilmente construídos
- Do ponto de vista dos usuários / desenvolvedores, por ter um grande apoio da comunidade, a resolução de problemas e depuração torna-se muito mais fácil
Seaborn
Conceitualizada e construída originalmente na Universidade de Stanford, esta biblioteca fica em cima do matplotlib . Em certo sentido, ele tem alguns sabores de matpotlib enquanto, do ponto de visualização, é muito melhor do que matplotlib e também possui recursos adicionais. Abaixo estão suas vantagens
- Temas integrados ajudam a uma melhor visualização
- Funções estatísticas ajudando melhores percepções de dados
- Melhor estética e plotagens integradas
- Documentação útil com exemplos eficazes
Natureza da Visualização
Dependendo do número de variáveis usadas para traçar a visualização e o tipo de variáveis, pode haver diferentes tipos de gráficos que podemos usar para entender a relação. Com base na contagem de variáveis, poderíamos ter
- Gráfico univariado (envolve apenas uma variável)
- Gráfico bivariado (mais de uma variável é necessária)
Um gráfico univariado pode ser para uma variável contínua compreender a propagação e distribuição da variável, enquanto para uma variável discreta pode nos dizer a contagem
Da mesma forma, um gráfico bivariado para variável contínua pode exibir estatísticas essenciais, como correlação, pois uma variável contínua versus discreta pode nos levar a conclusões muito importantes, como compreender a distribuição de dados em diferentes níveis de uma variável categórica. Um gráfico bivariado entre duas variáveis discretas também pode ser desenvolvido.
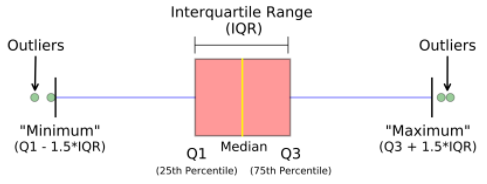
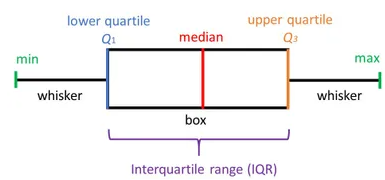
Box plot
Um boxplot, também conhecido como box e bigode, a caixa e o bigode são claramente exibidos na imagem abaixo. É uma representação visual muito boa quando se trata de medir a distribuição de dados. Plota claramente os valores medianos, outliers e os quartis. Compreender a distribuição de dados é outro fator importante que leva a uma melhor construção do modelo. Se os dados tiverem valores discrepantes, o gráfico de caixa é uma maneira recomendada de identificá-los e tomar as ações necessárias.
Sintaxe: seaborn.boxplot (x = None, y = None, hue = None, data = None, order = None, hue_order = None, orient = None, color = None, palette = None, saturation = 0.75, width = 0.8, dodge = True, fliersize = 5, linewidth = None, whis = 1.5, ax = None, ** kwargs)
Parâmetros:
x, y, hue: entradas para traçar dados de formato longo.
dados: Conjunto de dados para plotagem. Se x e y estiverem ausentes, isso será interpretado como formato amplo.
color: cor para todos os elementos.Retorna: Retorna o objeto Axes com o gráfico desenhado nele.
O gráfico de caixa e bigodes mostra como os dados são distribuídos. Cinco informações geralmente são incluídas no gráfico
- O mínimo é mostrado na extremidade esquerda do gráfico, no final do 'bigode' esquerdo
- O primeiro quartil, Q1, é a extremidade esquerda da caixa (bigode esquerdo)
- A mediana é mostrada como uma linha no centro da caixa
- Terceiro quartil, Q3, mostrado na extremidade direita da caixa (bigode direito)
- O máximo está na extremidade direita da caixa
Como pode ser visto nas representações e gráficos abaixo, um gráfico de caixa pode ser traçado para uma ou mais de uma variável, fornecendo insights muito bons para nossos dados.
Representação de box plot.
Box plot que representa variáveis categóricas multivariadas
Box plot que representa variáveis categóricas multivariadas
importmatplotlib as pltimportseaborn as sns_, axes=plt.subplots(1,2, sharey=True, figsize=(10,4))sns.boxplot(x='Outcome', y='BloodPressure', data=diabetes, ax=axes[0])sns.violinplot(x='Outcome', y='BloodPressure', data=diabetes, ax=axes[1])
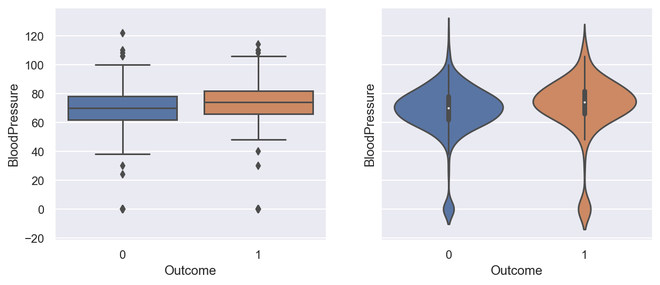
Saída para Box Plot e Violin Plot
sns.set(rc={'figure.figsize': (16,5)})sns.boxplot(data=diabetes.select_dtypes(include='number'))
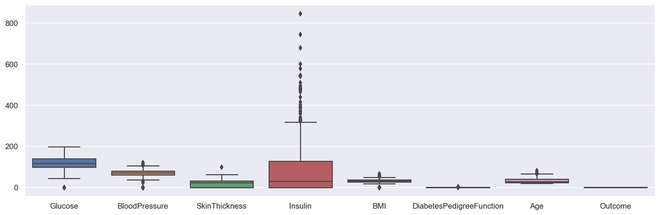
Output Multiple Box PLot
Gráfico de dispersão
Gráficos de dispersão ou gráficos de dispersão são gráficos bivariados com maior semelhança com os gráficos de linha na forma como são construídos. Um gráfico de linha usa uma linha em um eixo XY para traçar uma função contínua, enquanto um gráfico de dispersão se baseia em pontos para representar partes individuais de dados. Esses gráficos são muito úteis para ver se duas variáveis estão correlacionadas. O gráfico de dispersão pode ser bidimensional ou tridimensional.
Sintaxe: seaborn.scatterplot (x = None, y = None, hue = None, style = None, size = None, data = None, palette = None, hue_order = None, hue_norm = None, tamanhos = None, size_order = None, size_norm = None, markers = True, style_order = None, x_bins = None, y_bins = None, units = None, estimator = None, ci = 95, n_boot = 1000, alpha = 'auto', x_jitter = None, y_jitter = None, legend = 'brief', ax = None, ** kwargs)
Parâmetros:
x, y: variáveis de dados de entrada que devem ser numéricas.dados : Dataframe onde cada coluna é uma variável e cada linha é uma observação.
tamanho : Variável de agrupamento que produzirá pontos com tamanhos diferentes.
style : Variável de agrupamento que produzirá pontos com marcadores diferentes.
paleta : Variável de agrupamento que produzirá pontos com diferentes marcadores.
marcadores : Objeto que determina como desenhar os marcadores para diferentes níveis.
alfa : opacidade proporcional dos pontos.
Retorna: Este método retorna o objeto Axes com o gráfico desenhado nele.
Vantagens de um gráfico de dispersão
- Mostra a correlação entre as variáveis
- Adequado para grandes conjuntos de dados
- Mais fácil de encontrar clusters de dados
- Melhor representação de cada ponto de dados
importmatpotlib.pyplot as pltplt.scatter(diabetes['DiabetesPedigreeFunction'], diabetes['BMI'])
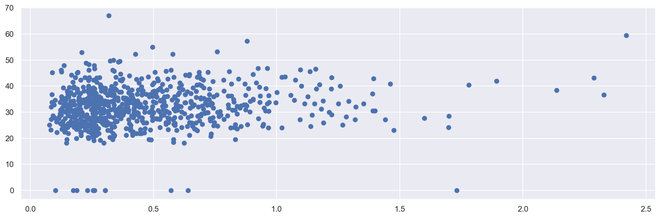
Gráfico disperso 2D de saída
frommpl_toolkits.mplot3dimportAxes3Dx=[1,2,3,4,5,6,7,8,9,10]y=[5,6,2,3,13,4,1,2,4,8]z=[2,3,3,3,5,7,9,11,9,10]sns.set(rc={'figure.figsize': (8,5)})fig=plt.figure()ax=fig.add_subplot(111, projection='3d')ax.scatter(x, y, z, c='r', marker='o')ax.set_xlabel('X Label'), ax.set_ylabel('Y Label'), ax.set_zlabel('Z Label')plt.show()
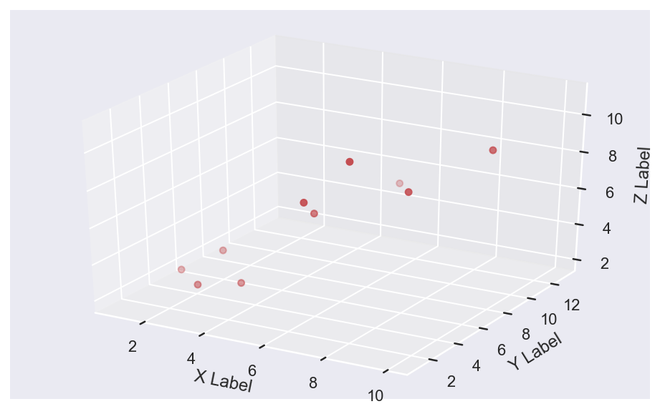
Gráfico de saída 3D espalhado
Histograma
Os histogramas exibem contagens de dados e, portanto, são semelhantes a um gráfico de barras. Um gráfico de histograma também pode nos dizer quão próxima uma distribuição de dados está de uma curva normal. Enquanto trabalhamos no método estatístico, é muito importante que tenhamos dados que normalmente ou próximos de uma distribuição normal. No entanto, os histogramas são univariados por natureza e os gráficos de barras bivariados .
Um gráfico de barras representa as contagens reais em relação às categorias, por exemplo, a altura da barra indica o número de itens nessa categoria, enquanto um histograma exibe as mesmas variáveis categóricas em caixas .
Os compartimentos são parte integrante ao construir um histograma, eles controlam os pontos de dados que estão dentro de um intervalo. Como uma escolha amplamente aceita, geralmente limitamos bin a um tamanho de 5-20, no entanto, isso é totalmente controlado pelos pontos de dados que estão presentes.
features=['BloodPressure','SkinThickness']diabetes[features].hist(figsize=(10,4))
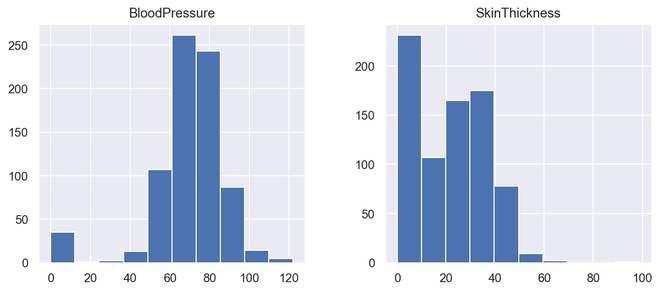
Histograma de saída
Countplot
Um gráfico de contagem é um gráfico entre uma variável categórica e uma contínua. A variável contínua, neste caso, é o número de vezes que a categórica está presente ou simplesmente a frequência. Em certo sentido, pode-se dizer que o gráfico de contagem está intimamente ligado a um histograma ou gráfico de barras.
Sintaxe: seaborn.countplot (x = None, y = None, hue = None, data = None, order = None, hue_order = None, orient = None, color = None, palette = None, saturation = 0.75, dodge = True, ax = None, ** kwargs)
Parâmetros: Este método está aceitando os seguintes parâmetros descritos abaixo:
- x, y: Este parâmetro recebe nomes de variáveis em dados ou dados vetoriais, opcional, entradas para traçar dados de formato longo.
- matiz: (opcional) Este parâmetro leva o nome da coluna para codificação de cores.
- data: (opcional) Este parâmetro leva DataFrame, array ou lista de arrays, Dataset para plotagem. Se x e y estiverem ausentes, isso será interpretado como formato amplo. Caso contrário, espera-se que seja longo.
- order, hue_order: (opcional) Este parâmetro leva listas de strings. Ordem para plotar os níveis categóricos, caso contrário, os níveis são inferidos dos objetos de dados.
- orient: (opcional) Este parâmetro leva “v” | “H”, Orientação da plotagem (vertical ou horizontal). Isso geralmente é inferido do tipo d das variáveis de entrada, mas pode ser usado para especificar quando a variável “categórica” é numérica ou ao plotar dados de formato largo.
- color: (opcional) Este parâmetro pega matplotlib color, Color para todos os elementos ou seed para uma paleta de gradiente.
- paleta: (opcional) Este parâmetro leva o nome da paleta, lista ou dicionário de cores para usar para os diferentes níveis da variável de matiz. Deve ser algo que possa ser interpretado por color_palette(), ou um dicionário que mapeie níveis de matiz para cores matplotlib.
- saturação: (opcional) Este parâmetro assume o valor flutuante, proporção da saturação original para desenhar as cores. Patches grandes geralmente ficam melhor com cores ligeiramente dessaturadas, mas defina como 1 se quiser que as cores do gráfico correspondam perfeitamente às especificações de cores de entrada.
- dodge: (opcional) Este parâmetro assume o valor bool, quando o aninhamento de matiz é usado, se os elementos devem ser deslocados ao longo do eixo categórico.
- ax: (opcional) Este parâmetro leva matplotlib Axes, Axes objeto para desenhar o gráfico, caso contrário, usa os eixos atuais.
- kwargs: Este parâmetro leva chave, mapeamentos de valor, outros argumentos de palavra-chave são passados para matplotlib.axes.Axes.bar().
Retorna: Retorna o objeto Axes com o gráfico desenhado nele.
Ele simplesmente mostra o número de ocorrências de um item com base em um certo tipo de category.In python, podemos criar um counplot usando o Seaborn biblioteca. Seaborn é um módulo em Python que é construído sobre matplotlib e usado para gráficos estatísticos visualmente atraentes.
importseaborn as sns_, axes=plt.subplots(nrows=1, ncols=2, figsize=(12,4))sns.countplot(x='Outcome', data=diabetes, ax=axes[0])sns.countplot(x='BloodPressure', data=diabetes, ax=axes[1])
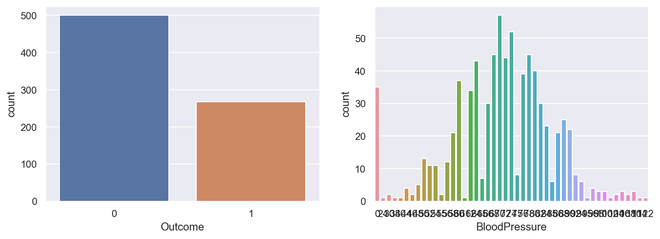
Output Countplot
Gráfico de correlação
O gráfico de correlação é uma análise multivariada que é muito útil para observar o relacionamento com os pontos de dados. Os gráficos de dispersão ajudam a entender o efeito de uma variável sobre a outra. A correlação pode ser definida como o efeito que uma variável tem sobre a outra.
A correlação pode ser calculada entre duas variáveis ou pode ser uma contra muitas correlações também, que podemos ver no gráfico abaixo. A correlação pode ser positiva, negativa ou neutra e o intervalo matemático de correlações é de -1 a 1. A compreensão da correlação pode ter um efeito muito significativo no estágio de construção do modelo e também a compreensão dos resultados do modelo.
importseaborn as snssns.set(rc={'figure.figsize': (14,5)})ind_var=['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT']sns.heatmap(diabetes.select_dtypes(include='number').corr(),cmap=sns.cubehelix_palette(20, light=0.95, dark=0.15))
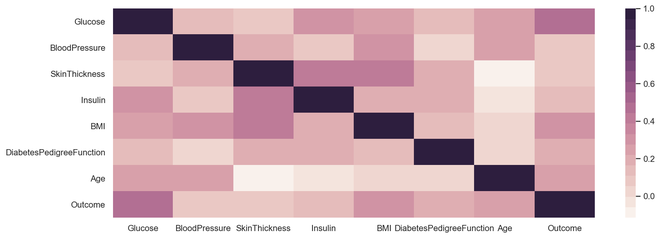
Gráfico de correlação de saída
Mapas de Calor
O mapa de calor é uma representação de dados multivariada. A intensidade da cor em uma exibição de mapa de calor torna-se um fator importante para entender o efeito dos pontos de dados. Os mapas de calor são mais fáceis de entender e também de explicar. Quando se trata de análise de dados usando visualização, é muito importante que a mensagem desejada seja transmitida com a ajuda de gráficos.
Sintaxe:
seaborn.heatmap ( data , * , vmin = None , vmax = None , cmap = None , center = None , robust = False , annot = None , fmt = '. 2g' , annot_kws = None , linewidths = 0 , linecolor = ' white ' , cbar = True , cbar_kws = None , cbar_ax = None , square = False , xticklabels =' auto ' , yticklabels =' auto ' , mask = None , ax = None , ** kwargs )
Parâmetros: este método aceita os seguintes parâmetros descritos a seguir:
- x, y: Este parâmetro recebe nomes de variáveis em dados ou dados vetoriais, opcional, entradas para traçar dados de formato longo.
- matiz: (opcional) Este parâmetro leva o nome da coluna para codificação de cores.
- data: (opcional) Este parâmetro leva DataFrame, array ou lista de arrays, Dataset para plotagem. Se x e y estiverem ausentes, isso será interpretado como formato amplo. Caso contrário, espera-se que seja longo.
- color: (opcional) Este parâmetro pega matplotlib color, Color para todos os elementos ou seed para uma paleta de gradiente.
- paleta: (opcional) Este parâmetro leva o nome da paleta, lista ou dicionário de cores para usar para os diferentes níveis da variável de matiz. Deve ser algo que possa ser interpretado por color_palette(), ou um dicionário que mapeie níveis de matiz para cores matplotlib.
- ax: (opcional) Este parâmetro leva matplotlib Axes, Axes objeto para desenhar o gráfico, caso contrário, usa os eixos atuais.
- kwargs: Este parâmetro leva chave, mapeamentos de valor, outros argumentos de palavra-chave são passados para matplotlib.axes.Axes.bar().
Retorna: Retorna o objeto Axes com o gráfico desenhado nele.
importseaborn as snsimportnumpy as npdata=np.random.randn(50,20)ax=sns.heatmap(data, xticklabels=2, yticklabels=False)
Mapa de calor de saída
Gráfico de pizza
O gráfico de pizza é uma análise univariada e normalmente é usado para mostrar dados percentuais ou proporcionais. A distribuição percentual de cada classe em uma variável é fornecida ao lado da fatia correspondente do bolo. As bibliotecas python que podem ser usadas para construir um gráfico de pizza são matplotlib e seaborn.
Sintaxe: matplotlib.pyplot.pie (data, explode = None, labels = None, colors = None, autopct = None, shadow = False)
Parâmetros:
dados representam a matriz de valores de dados a serem plotados, a área fracionária de cada fatia é representada por dados / soma (dados) . Se sum (dados) <1, então os valores dos dados retornam a área fracionária diretamente, portanto, a pizza resultante terá uma fatia vazia de tamanho 1-soma (dados).
rótulos é uma lista de sequência de strings que define o rótulo de cada cunha.
O atributo color é usado para fornecer cor às cunhas.
autopct é uma string usada para rotular a cunha com seu valor numérico.
a sombra é usada para criar a sombra da cunha.
Abaixo estão as vantagens de um gráfico de pizza
- Resumo visual mais fácil de grandes pontos de dados
- O efeito e o tamanho das diferentes classes podem ser facilmente compreendidos
- Os pontos percentuais são usados para representar as classes nos pontos de dados
importmatplotlib.pyplot as pltcars=['AUDI','BMW','FORD','TESLA','JAGUAR','MERCEDES']data=[23,17,35,29,12,41]fig=plt.figure(figsize=(10,7))plt.pie(data, labels=cars)plt.show()
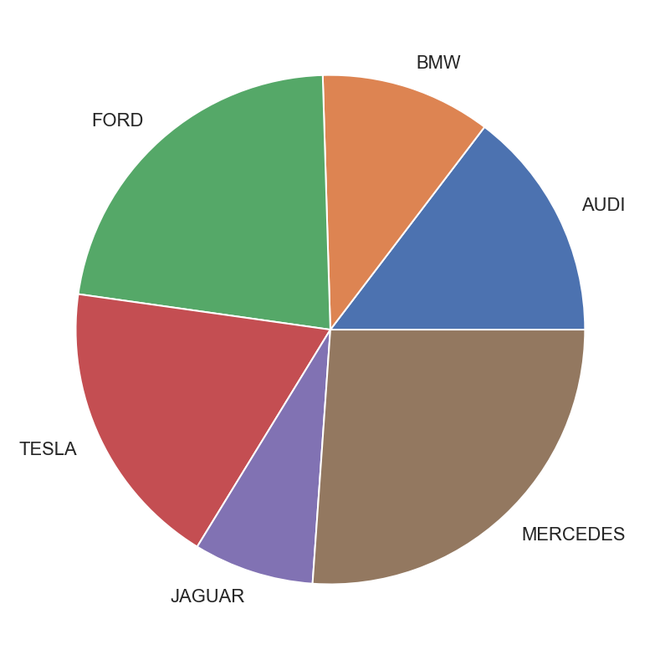
Gráfico de pizza de saída
importmatplotlib.pyplot as pltimportnumpy as npcars=['AUDI','BMW','FORD','TESLA','JAGUAR','MERCEDES']data=[23,17,35,29,12,41]explode=(0.1,0.0,0.2,0.3,0.0,0.0)colors=("orange","cyan","brown","grey","indigo","beige")wp={'linewidth':1,'edgecolor':"green"}deffunc(pct, allvalues):absolute=int(pct/100.*np.sum(allvalues))return"{:.1f}%\n({:d} g)".format(pct, absolute)fig, ax=plt.subplots(figsize=(10,7))wedges, texts, autotexts=ax.pie(data, autopct=lambdapct: func(pct, data), explode=explode, labels=cars,shadow=True, colors=colors, startangle=90, wedgeprops=wp,textprops=dict(color="magenta"))ax.legend(wedges, cars, title="Cars", loc="center left",bbox_to_anchor=(1,0,0.5,1))plt.setp(autotexts, size=8, weight="bold")ax.set_title("Customizing pie chart")plt.show()
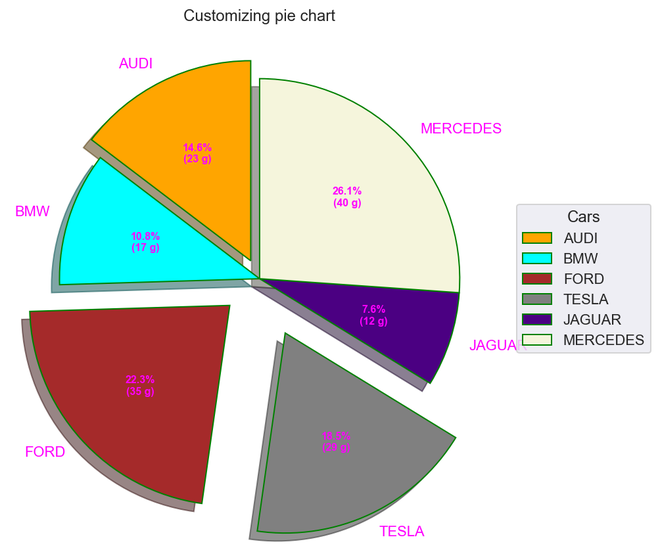
Resultado
Barras de erro
As barras de erro podem ser definidas como uma linha que passa por um ponto em um gráfico, paralela a um dos eixos, que representa a incerteza ou o erro da coordenada correspondente do ponto. Esses tipos de gráficos são muito úteis para entender e analisar os desvios do alvo. Uma vez identificados os erros, isso pode facilmente levar a uma análise mais profunda dos fatores que os causam.
- O desvio dos pontos de dados do limite pode ser facilmente capturado
- Captura facilmente desvios de um conjunto maior de pontos de dados
- Ele define os dados subjacentes
importmatplotlib.pyplot as pltimportnumpy as npx=np.linspace(0,5.5,10)y=10*np.exp(-x)xerr=np.random.random_sample(10)yerr=np.random.random_sample(10)fig, ax=plt.subplots()ax.errorbar(x, y, xerr=xerr, yerr=yerr, fmt='-o')ax.set_xlabel('x-axis'), ax.set_ylabel('y-axis')ax.set_title('Line plot with error bars')plt.show()
Gráfico de erro de saída
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva