Assistente de voz pessoal em Python
Como sabemos, Python é uma linguagem adequada para escritores e desenvolvedores de scripts. Vamos escrever um script para o Personal Voice Assistant usando Python. A consulta do assistente pode ser manipulada conforme a necessidade do usuário.
O assistente implementado pode abrir o aplicativo (se estiver instalado no sistema), pesquisar no Google, Wikipedia e YouTube sobre a consulta, calcular qualquer questão matemática, etc. apenas dando o comando de voz . Podemos processar os dados conforme a necessidade ou podemos adicionar a funcionalidade, depende de como codificamos as coisas.
Estamos usando a API de reconhecimento de voz do Google e o texto em fala do google para entrada e saída de voz, respectivamente.
Além disso, para calcular a expressão matemática, a API WolframAlpha pode ser usada.
O pacote Playsound é usado para reproduzir o som mp3 salvo do sistema.
Requisitos de pacote externo do Python:
-> gTTS - Google Text To Speech, para converter o texto fornecido em fala
-> speech_recognition - para reconhecer o comando de voz e converter em texto
-> selenium - para trabalho baseado na web a partir do navegador
-> wolframalpha - para cálculo fornecido pelo usuário
-> playound - para reproduzir o arquivo de áudio salvo.
-> pyaudio - para mecanismo de voz em python
Bem, vamos começar com o código. Vamos dividir cada função como um único código para facilitar o entendimento.
Aqui está a função principal, com get_audio()e assistant_speaks função. get_audio()função é criada para obter o áudio do usuário usando o microfone, o limite de frase é definido para 5 segundos (você pode alterá-lo). A função de fala do assistente é criada para fornecer a saída de acordo com os dados processados.
importspeech_recognition as srimportplaysoundfromgttsimportgTTSimportosimportwolframalphafromseleniumimportwebdrivernum=1defassistant_speaks(output):globalnumnum+=1("PerSon : ", output)toSpeak=gTTS(text=output, lang='en', slow=False)file=str(num)+".mp3toSpeak.save(file)playsound.playsound(file,True)os.remove(file)defget_audio():rObject=sr.Recognizer()audio=''with sr.Microphone() as source:("Speak...")audio=rObject.listen(source, phrase_time_limit=5)("Stop.")try:text=rObject.recognize_google(audio, language='en-US')("You : ", text)returntextexcept:assistant_speaks("Could not understand your audio, PLease try again !")return0if__name__=="__main__":assistant_speaks("What's your name, Human?")name='Human'name=get_audio()assistant_speaks("Hello, "+name+'.')while(1):assistant_speaks("What can i do for you?")text=get_audio().lower()iftext==0:continueif"exit"instr(text)or"bye"instr(text)or"sleep"instr(text):assistant_speaks("Ok bye, "+name+'.')breakprocess_text(text)
Aqui estão alguns dos exemplos e resultados, que podem ajudá-lo a entender como funciona o processamento acima.
1. Diga "Pesquisar Geeks do Google por Geeks" 2. Diga "Tocar no Youtube sua música favorita" 3. Diga "Wikipedia Dhoni" 4. Diga "Open Microsoft Word" 5. Diga "Calcule o que quiser"
Em todos os casos acima, ele fará o que for mandado. Se o assistente não puder entender o que é dito, ele pedirá que você faça uma busca no Google. Pois o que o assistente não pode fazer é controlado por este assistente.
Abaixo estão algumas imagens da conversa entre o humano e o assistente.
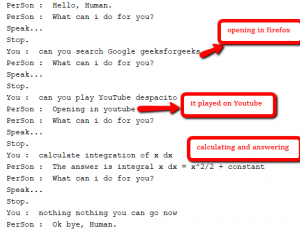

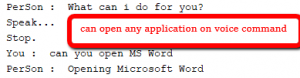
Bem, é isso. A funcionalidade acima pode ser codificada de várias maneiras, esta é uma implementação básica. Certifique-se de ter a versão mais recente de todos os pacotes acima para um trabalho tranquilo. Para executar o código acima, combine todas as funções no mesmo arquivo.
Encontre abaixo um pequeno vídeo para a compilação do código acima.
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva