Indexação Booleana em Pandas
Na indexação booleana, selecionaremos subconjuntos de dados com base nos valores reais dos dados no DataFrame e não em seus rótulos de linha / coluna ou localizações de inteiros. Na indexação booleana, usamos um vetor booleano para filtrar os dados.

A indexação booleana é um tipo de indexação que usa valores reais dos dados no DataFrame. Na indexação booleana, podemos filtrar dados de quatro maneiras -
- Acessando um DataFrame com um índice booleano
- Aplicar uma máscara booleana a um dataframe
- Mascarando dados com base no valor da coluna
- Mascarando dados com base no valor do índice
Acessando um DataFrame com um índice booleano:
Para acessar um dataframe com um índice booleano, temos que criar um dataframe no qual o índice do dataframe contenha um valor booleano que seja “True” ou “False”. Por exemplo
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict, index = [True, False, True, False])
print(df)Saída:
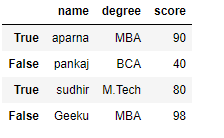
Agora criamos um dataframe com índice booleano depois que o usuário pode acessar um dataframe com a ajuda do índice booleano. O usuário pode acessar um dataframe usando três funções que são .loc [], .iloc [], .ix []
Acessando um Dataframe com um índice booleano usando .loc []
Para acessar um dataframe com um índice booleano usando .loc [], simplesmente passamos um valor booleano (Verdadeiro ou Falso) em uma função .loc [].
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
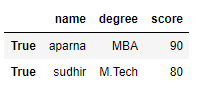
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .loc[] function
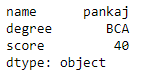
print(df.loc[True])Saída:
Acessando um Dataframe com um índice booleano usando .iloc []
Para acessar um dataframe usando .iloc [], temos que passar um valor booleano (True ou False), mas a função iloc [] aceita apenas números inteiros como argumento, então ele irá gerar um erro, então só podemos acessar um dataframe quando passarmos um número inteiro no código de função iloc []
1:
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .iloc[] function
print(df.iloc[True])Saída:
TypeError
Código # 2:
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
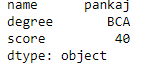
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .iloc[] function
print(df.iloc[1])Saída:
Acessando um Dataframe com um índice booleano usando .ix []
Para acessar um dataframe usando .ix [], temos que passar o valor booleano (Verdadeiro ou Falso) e o valor inteiro para a função .ix [] porque, como sabemos, a função .ix [] é um híbrido de .loc [] e função .iloc [].
Código # 1:
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
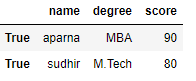
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .ix[] function
print(df.ix[True])Saída:
Código # 2:
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe with boolean index
df = pd.DataFrame(dict, index = [True, False, True, False])
# accessing a dataframe using .ix[] function
print(df.ix[1])Saída:
Aplicando uma máscara booleana a um dataframe:
Em um dataframe podemos aplicar uma máscara booleana para fazer isso, podemos usar __getitems__ ou [] acessor. Podemos aplicar uma máscara booleana fornecendo uma lista de True e False do mesmo comprimento que a contida em um dataframe. Quando aplicamos uma máscara booleana, ela imprimirá apenas aquele dataframe no qual passamos um valor booleano True. Para baixar o arquivo CSV “ nba1.1 ” clique aqui .
Código # 1:
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict, index = [0, 1, 2, 3])
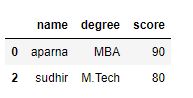
print(df[[True, False, True, False]])Saída:
Código # 2:
# importing pandas package
import pandas as pd
# making data frame from csv file
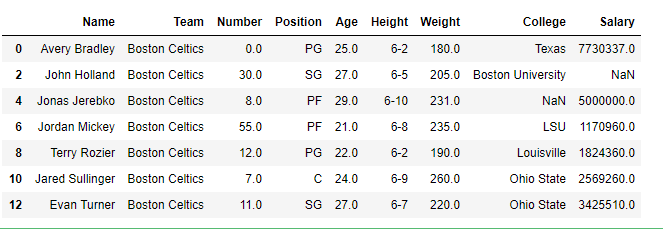
data = pd.read_csv("nba1.1.csv")
df = pd.DataFrame(data, index = [0, 1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12])
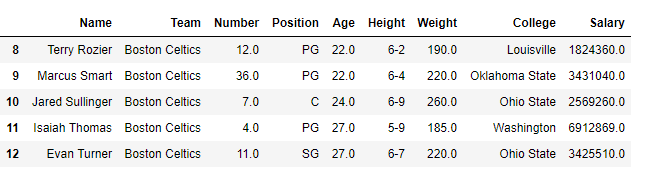
df[[True, False, True, False, True,
False, True, False, True, False,
True, False, True]]Saída:
Mascarando dados com base no valor da coluna:
em um dataframe podemos filtrar dados com base em um valor de coluna para filtrar os dados, podemos aplicar certas condições no dataframe usando diferentes operadores como ==,>, <, <=,> =. Quando aplicamos esses operadores no dataframe, eles produzem uma série de verdadeiro e falso. Para baixar o CSV “nba.csv”, clique aqui .
Código # 1:
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["BCA", "BCA", "M.Tech", "BCA"],
'score':[90, 40, 80, 98]}
# creating a dataframe
df = pd.DataFrame(dict)
# using a comparison operator for filtering of data
print(df['degree'] == 'BCA')Saída:

Código # 2:
# importing pandas package
import pandas as pd
# making data frame from csv file
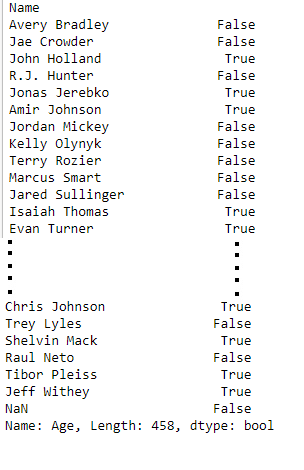
data = pd.read_csv("nba.csv", index_col ="Name")
# using greater than operator for filtering of data
print(data['Age'] > 25)Saída:
Mascarando dados com base no valor do índice:
Em um dataframe podemos filtrar os dados com base no valor de uma coluna para filtrar os dados, podemos criar uma máscara com base nos valores do índice usando diferentes operadores como ==,>, <, etc…. Para baixar o arquivo CSV “ nba1.1 ” clique aqui .
Código # 1:
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["BCA", "BCA", "M.Tech", "BCA"],
'score':[90, 40, 80, 98]}
df = pd.DataFrame(dict, index = [0, 1, 2, 3])
mask = df.index == 0
print(df[mask])Saída:

Código # 2:
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba1.1.csv")
# giving a index to a dataframe
df = pd.DataFrame(data, index = [0, 1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12])
# filtering data on index value
mask = df.index > 7
df[mask]Saída:
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva