Introdução às máquinas de vetores de suporte (SVM)
O que são máquinas de vetores de suporte? No SVM, plotamos cada item de dados no conjunto de dados em um espaço N-dimensional, onde N é o número de recursos / atributos nos dados. Em seguida, encontre o hiperplano ideal para separar os dados. Portanto, com isso, você deve ter entendido que, inerentemente, o SVM só pode realizar a classificação binária (ou seja, escolher entre duas classes). No entanto, existem várias técnicas a serem usadas para problemas com várias classes. Máquina de vetores de suporte para problemas multiclasse Para executar SVM em problemas multiclasse , podemos criar um classificador binário para cada classe dos dados. Os dois resultados de cada classificador serão:
Support Vector Machine (SVM) é um algoritmo de aprendizado de máquina supervisionado relativamente simples usado para classificação e / ou regressão. É mais preferido para classificação, mas às vezes também é muito útil para regressão. Basicamente, o SVM encontra um hiperplano que cria uma fronteira entre os tipos de dados. No espaço bidimensional, este hiperplano nada mais é do que uma linha.
- O ponto de dados pertence a essa classe OU
- O ponto de dados não pertence a essa classe.
Por exemplo, em uma classe de frutas, para realizar a classificação multiclasse, podemos criar um classificador binário para cada fruta. Por exemplo, a classe 'manga', haverá um classificador binário para prever se é uma manga OU NÃO é uma manga. O classificador com a pontuação mais alta é escolhido como a saída do SVM.
SVM para dados complexos (não linearmente separáveis) O
SVM funciona muito bem sem nenhuma modificação para dados separáveis linearmente. Dados linearmente separáveis são quaisquer dados que podem ser plotados em um gráfico e podem ser separados em classes usando uma linha reta.
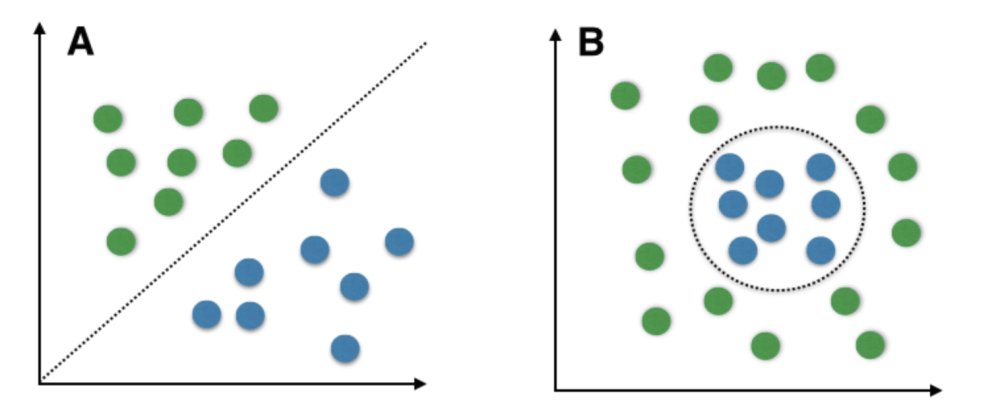
A: Dados separáveis linearmente B: Dados separáveis não linearmente
Um kernel não é nada uma medida de similaridade entre pontos de dados. A função kernel em um SVM kernelizado informa, dados dois pontos de dados no espaço de recurso original, qual é a similaridade entre os pontos no espaço de recurso recém-transformado.
Existem várias funções do kernel disponíveis, mas duas delas são muito populares:
- Radial Basis Function Kernel (RBF): A similaridade entre dois pontos no espaço do recurso transformado é uma função exponencialmente decrescente da distância entre os vetores e o espaço de entrada original, conforme mostrado abaixo. RBF é o kernel padrão usado em SVM.

- Kernel polinomial: O kernel polinomial tem um parâmetro adicional, 'grau' que controla a complexidade do modelo e o custo computacional da transformação
Um fato muito interessante é que o SVM não precisa realmente realizar essa transformação real nos pontos de dados para o novo espaço de recursos de alta dimensão. Isso é chamado de truque do kernel .
O truque do kernel:
internamente, o SVM kernelizado pode computar essas transformações complexas apenas em termos de cálculos de similaridade entre pares de pontos no espaço de recurso dimensional superior onde a representação do recurso transformado está implícita.
Essa função de similaridade, que é matematicamente um tipo de produto escalar complexo, é na verdade o kernel de um SVM kernelizado. Isso torna prático aplicar SVM, quando o espaço de recursos subjacente é complexo, ou mesmo de dimensão infinita. O truque do kernel em si é bastante complexo e está além do escopo deste artigo.
Parâmetros importantes em SVC com kernel (classificador de vetores de suporte)
- O Kernel : O kernel, é selecionado com base no tipo de dados e também no tipo de transformação. Por padrão, o kernel é Radial Basis Function Kernel (RBF).
- Gama : este parâmetro decide até que ponto a influência de um único exemplo de treinamento atinge durante a transformação, o que, por sua vez, afeta a intensidade com que os limites de decisão acabam envolvendo os pontos no espaço de entrada. Se houver um pequeno valor de gama, os pontos mais distantes são considerados semelhantes. Portanto, mais pontos são agrupados e têm limites de decisão mais suaves (podem ser menos precisos). Valores maiores de gama fazem com que os pontos fiquem mais próximos (pode causar sobreajuste).
- O parâmetro 'C' : este parâmetro controla a quantidade de regularização aplicada aos dados. Valores grandes de C significam baixa regularização que, por sua vez, faz com que os dados de treinamento se ajustem muito bem (pode causar sobreajuste). Valores mais baixos de C significam maior regularização, o que faz com que o modelo seja mais tolerante a erros (pode levar a uma menor precisão).
Prós do SVM com kernel:
- Eles funcionam muito bem em uma variedade de conjuntos de dados.
- Eles são versáteis: diferentes funções do kernel podem ser especificadas, ou kernels personalizados também podem ser definidos para tipos de dados específicos.
- Eles funcionam bem para dados dimensionais altos e baixos.
Contras do SVM Kernelizado:
- A eficiência (tempo de execução e uso de memória) diminui à medida que o tamanho do conjunto de treinamento aumenta.
- Precisa de normalização cuidadosa dos dados de entrada e ajuste de parâmetros.
- Não fornece estimador de probabilidade direto.
- Difícil de interpretar porque uma previsão foi feita.
CONCLUSÃO
Agora que você conhece o básico de como funciona um SVM, pode acessar o seguinte link para aprender como implementar o SVM para classificar itens usando Python:
https://www.geeksforgeeks.org/classifying-data-using-support-vector-machinessvms-in-python/
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva