Introdução ao TensorFlow
Este artigo é uma breve introdução à biblioteca TensorFlow usando a linguagem de programação Python.
Introdução
TensorFlow é uma biblioteca de software de código aberto. O TensorFlow foi originalmente desenvolvido por pesquisadores e engenheiros que trabalham na equipe do Google Brain dentro da organização de pesquisa de inteligência de máquina do Google com o objetivo de conduzir pesquisas de machine learning e redes neurais profundas, mas o sistema é geral o suficiente para ser aplicável em uma ampla variedade de outros domínios, como bem!
Vamos primeiro tentar entender o que a palavra TensorFlow realmente significa!
O TensorFlow é basicamente uma biblioteca de software para computação numérica usando gráficos de fluxo de dados onde:
- os nós no gráfico representam operações matemáticas.
- as arestas no gráfico representam as matrizes de dados multidimensionais (chamados tensores ) comunicados entre eles. (Observe que tensor é a unidade central de dados no TensorFlow).
Considere o diagrama abaixo:
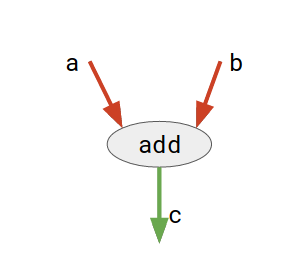
Aqui, add é um nó que representa a operação de adição. a e b são tensores de entrada e c é o tensor resultante.
Esta arquitetura flexível permite que você implante computação em uma ou mais CPUs ou GPUs em um desktop, servidor ou dispositivo móvel com uma única API!
APIs TensorFlow
O TensorFlow fornece várias APIs (interfaces de programação de aplicativos). Eles podem ser classificados em 2 categorias principais:
- API de baixo nível:
- controle de programação completo
- recomendado para pesquisadores de machine learning
- fornece bons níveis de controle sobre os modelos
- TensorFlow Core é a API de baixo nível do TensorFlow.
- API de alto nível:
- construído sobre o TensorFlow Core
- mais fácil de aprender e usar do que o TensorFlow Core
- tornar as tarefas repetitivas mais fáceis e mais consistentes entre diferentes usuários
- tf.contrib.learn é um exemplo de API de alto nível.
Neste artigo, primeiro discutimos os fundamentos do TensorFlow Core e, em seguida, exploramos a API de nível superior, tf.contrib.learn .
TensorFlow Core
1. Instalação do TensorFlow
Um guia fácil de seguir para a instalação do TensorFlow está disponível aqui:
Instalando o TensorFlow .
Depois de instalado, você pode garantir uma instalação bem-sucedida executando este comando no interpretador Python:
importar tensorflow como tf
2. O gráfico computacional
Qualquer programa TensorFlow Core pode ser dividido em duas seções distintas:
- Construindo o gráfico computacional. Um gráfico computacional nada mais é do que uma série de operações do TensorFlow organizadas em um gráfico de nós.
- Executando o gráfico computacional. Para realmente avaliar os nós, devemos executar o gráfico computacional em uma sessão . Uma sessão encapsula o controle e o estado do tempo de execução do TensorFlow.
Agora, vamos escrever nosso primeiro programa TensorFlow para entender o conceito acima:
importtensorflow as tfnode1=tf.constant(3, dtype=tf.int32)node2=tf.constant(5, dtype=tf.int32)node3=tf.add(node1, node2)sess=tf.Session()("Sum of node1 and node2 is:",sess.run(node3))sess.close()
Resultado:
A soma de node1 e node2 é: 8
Vamos tentar entender o código acima:
- Etapa 1: Criar um gráfico computacional
Ao criar um gráfico computacional, queremos dizer definir os nós. O Tensorflow oferece diferentes tipos de nós para uma variedade de tarefas. Cada nó recebe zero ou mais tensores como entradas e produz um tensor como saída.- No programa acima, os nós node1 e node2 são do tipo tf.constant . Um nó constante não aceita entradas e produz um valor que armazena internamente. Observe que também podemos especificar o tipo de dados do tensor de saída usando o argumento dtype .
node1 = tf.constant (3, dtype = tf.int32) node2 = tf.constant (5, dtype = tf.int32)
- node3 é do tipo tf.add . Leva dois tensores como entrada e retorna sua soma como tensor de saída.
node3 = tf.add (node1, node2)
- No programa acima, os nós node1 e node2 são do tipo tf.constant . Um nó constante não aceita entradas e produz um valor que armazena internamente. Observe que também podemos especificar o tipo de dados do tensor de saída usando o argumento dtype .
- Etapa 2: Executar o gráfico computacional
Para executar o gráfico computacional, precisamos criar uma sessão . Para criar uma sessão, simplesmente fazemos:
sess = tf.Session()
Agora, podemos invocar o método run do objeto de sessão para realizar cálculos em qualquer nó:
print ("A soma de node1 e node2 é:", sess.run (node3))Aqui, node3 é avaliado, o que invoca ainda mais node1 e node2 . Finalmente, fechamos a sessão usando:
sess.close()
Nota: Outro (e melhor) método de trabalhar com sessões é usar blocos como este:
com tf.Session() as sess:
print ("A soma de node1 e node2 é:", sess.run (node3))
O benefício dessa abordagem é que você não precisa fechar a sessão explicitamente, pois ela é fechada automaticamente quando o controle sai do escopo com o bloco.
3. Variáveis
O TensorFlow também tem nós variáveis que podem conter dados variáveis. Eles são usados principalmente para manter e atualizar os parâmetros de um modelo de treinamento.
Variáveis são buffers na memória contendo tensores. Eles devem ser inicializados explicitamente e podem ser salvos no disco durante e após o treinamento. Posteriormente, você pode restaurar os valores salvos para exercitar ou analisar o modelo.
Uma diferença importante a ser observada entre uma constante e uma variável é:
O valor de uma constante é armazenado no gráfico e seu valor é replicado onde quer que o gráfico seja carregado. Uma variável é armazenada separadamente e pode residir em um servidor de parâmetros.
A seguir está um exemplo de uso de variável :
importtensorflow as tfnode=tf.Variable(tf.zeros([2,2]))with tf.Session() as sess:sess.run(tf.global_variables_initializer())("Tensor value before addition:\n",sess.run(node))node=node.assign(node+tf.ones([2,2]))("Tensor value after addition:\n", sess.run(node))
Resultado:
Valor do tensor antes da adição: [[0. 0.] [0. 0.]] Valor do tensor após adição: [[1. 1.] [1. 1.]]
No programa acima:
- Definimos um nó do tipo Variável e atribuímos a ele algum valor inicial.
node = tf.Variable (tf.zeros ([2,2]))
- Para inicializar o nó variável no escopo da sessão atual, fazemos:
sess.run (tf.global_variables_initializer())
- Para atribuir um novo valor a um nó variável, podemos usar o método de atribuição como este:
node = node.assign (node + tf.ones ([2,2]))
4. Marcadores
Um gráfico pode ser parametrizado para aceitar entradas externas, conhecidas como marcadores de posição . Um espaço reservado é uma promessa de fornecer um valor mais tarde.
Ao avaliar o gráfico envolvendo nós de espaço reservado , um parâmetro feed_dict é passado para o método de execução da sessão para especificar tensores que fornecem valores concretos para esses marcadores.
Considere o exemplo abaixo:
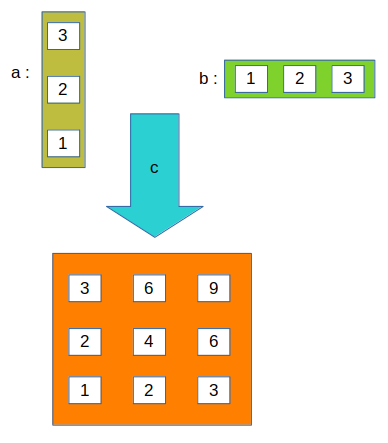
importtensorflow as tfa=tf.placeholder(tf.int32, shape=(3,1))b=tf.placeholder(tf.int32, shape=(1,3))c=tf.matmul(a,b)with tf.Session() as sess:(sess.run(c, feed_dict={a:[[3],[2],[1]], b:[[1,2,3]]}))
Resultado:
[[3 6 9] [2 4 6] [1 2 3]]
Vamos tentar entender o programa acima:
- Definimos os nós de espaço reservado a e b assim:
a = tf.placeholder (tf.int32, forma = (3,1)) b = tf.placeholder (tf.int32, forma = (1,3))
O primeiro argumento é o tipo de dados do tensor e um dos argumentos opcionais é a forma do tensor.
- Definimos outro nó c que faz a operação de multiplicação da matriz ( matmul ). Passamos os dois nós de espaço reservado como argumento.
c = tf.matmul (a, b)
- Finalmente, quando executar a sessão, passamos o valor de nós de espaço reservado em feed_dict argumento de sess.run :
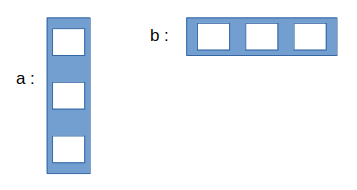
imprimir (sess.run (c, feed_dict = {a: [[3], [2], [1]], b: [[1,2,3]]}))Considere os diagramas mostrados abaixo para esclarecer o conceito:
- Inicialmente:
- Após sess.run:
5. Um exemplo: modelo de regressão linear
A seguir, é fornecida uma implementação de um modelo de regressão linear usando a API TensorFlow Core.
importtensorflow as tfimportnumpy as npimportmatplotlib.pyplot as pltlearning_rate=0.01training_epochs=2000display_step=200train_X=np.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,7.042,10.791,5.313,7.997,5.654,9.27,3.1])train_y=np.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,2.827,3.465,1.65,2.904,2.42,2.94,1.3])n_samples=train_X.shape[0]test_X=np.asarray([6.83,4.668,8.9,7.91,5.7,8.7,3.1,2.1])test_y=np.asarray([1.84,2.273,3.2,2.831,2.92,3.24,1.35,1.03])X=tf.placeholder(tf.float32)y=tf.placeholder(tf.float32)W=tf.Variable(np.random.randn(), name="weight")b=tf.Variable(np.random.randn(), name="bias")linear_model=W*X+bcost=tf.reduce_sum(tf.square(linear_model-y))/(2*n_samples)optimizer=tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)init=tf.global_variables_initializer()with tf.Session() as sess:sess.run(init)forepochinrange(training_epochs):sess.run(optimizer, feed_dict={X: train_X, y: train_y})if(epoch+1)%display_step==0:c=sess.run(cost, feed_dict={X: train_X, y: train_y})("Epoch:{0:6} \t Cost:{1:10.4} \t W:{2:6.4} \t b:{3:6.4}".format(epoch+1, c, sess.run(W), sess.run(b)))("Optimization Finished!")training_cost=sess.run(cost, feed_dict={X: train_X, y: train_y})("Final training cost:", training_cost,"W:", sess.run(W),"b:",sess.run(b),'\n')plt.plot(train_X, train_y,'ro', label='Original data')plt.plot(train_X, sess.run(W)*train_X+sess.run(b), label='Fitted line')plt.legend()plt.show()testing_cost=sess.run(tf.reduce_sum(tf.square(linear_model-y))/(2*test_X.shape[0]),feed_dict={X: test_X, y: test_y})("Final testing cost:", testing_cost)("Absolute mean square loss difference:",abs(training_cost-testing_cost))plt.plot(test_X, test_y,'bo', label='Testing data')plt.plot(train_X, sess.run(W)*train_X+sess.run(b), label='Fitted line')plt.legend()plt.show()
Época: 200 Custo: 0,1715 W: 0,426 b: -0,4371 Época: 400 Custo: 0,1351 W: 0,3884 b: -0,1706 Época: 600 Custo: 0,1127 W: 0,3589 b: 0,03849 Época: 800 Custo: 0,09894 W: 0,3358 b: 0,2025 Época: 1000 Custo: 0,09047 W: 0,3176 b: 0,3311 Época: 1200 Custo: 0,08526 W: 0,3034 b: 0,4319 Época: 1400 Custo: 0,08205 W: 0,2922 b: 0,5111 Época: 1600 Custo: 0,08008 W: 0,2835 b: 0,5731 Época: 1800 Custo: 0,07887 W: 0,2766 b: 0,6218 Época: 2000 Custo: 0,07812 W: 0,2712 b: 0,66 Otimização concluída! Custo de treinamento final: 0,0781221 W: 0,271219 b: 0,65996Custo do teste final: 0,0756337 Diferença de perda quadrada média absoluta: 0,00248838
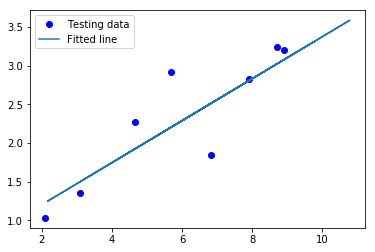
Vamos tentar entender o código acima.
- Em primeiro lugar, definimos alguns parâmetros para treinar nosso modelo, como:
learning_rate = 0,01 training_epochs = 2000 display_step = 200
- Em seguida, definimos nós de espaço reservado para recurso e vetor de destino.
X = tf.placeholder (tf.float32) y = tf.placeholder (tf.float32)
- Em seguida, definimos nós variáveis para peso e viés.
W = tf.Variable (np.random.randn(), nome = "peso") b = tf.Variable (np.random.randn(), name = "bias")
- linear_model é um nó operacional que calcula a hipótese para o modelo de regressão linear.
linear_model = W * X + b
- A perda (ou custo) por gradiente descendente é calculada como o erro quadrático médio e seu nó é definido como:
cost = tf.reduce_sum (tf.square (linear_model - y)) / (2 * n_samples)
- Finalmente, temos o nó otimizador que implementa o Gradient Descent Algorithm.
optimizer = tf.train.GradientDescentOptimizer (learning_rate) .minimize (cost)
- Agora, os dados de treinamento são ajustados ao modelo linear aplicando o Algoritmo Gradiente de Descida. A tarefa é repetida training_epochs número de vezes. Em cada época, realizamos a etapa de descida do gradiente assim:
sess.run (otimizador, feed_dict = {X: train_X, y: train_y}) - Após cada número display_step de épocas, imprimimos o valor da perda atual que é encontrada usando:
c = sess.run (custo, feed_dict = {X: train_X, y: train_y}) - O modelo é avaliado em dados de teste e testing_cost é calculado usando:
testing_cost = sess.run (tf.reduce_sum (tf.square (linear_model - y)) / (2 * test_X.shape [0]), feed_dict = {X: test_X, y: test_y})
tf.contrib.learn
tf.contrib.learn é uma biblioteca de alto nível do TensorFlow que simplifica a mecânica do machine learning, incluindo o seguinte:
- executando loops de treinamento
- executando loops de avaliação
- gerenciamento de conjuntos de dados
- gerenciamento de alimentação
Vamos tentar ver a implementação da regressão linear nos mesmos dados que usamos acima usando tf.contrib.learn .
importtensorflow as tfimportnumpy as npfeatures=[tf.contrib.layers.real_valued_column("X")]estimator=tf.contrib.learn.LinearRegressor(feature_columns=features)train_X=np.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,7.042,10.791,5.313,7.997,5.654,9.27,3.1])train_y=np.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,2.827,3.465,1.65,2.904,2.42,2.94,1.3])test_X=np.asarray([6.83,4.668,8.9,7.91,5.7,8.7,3.1,2.1])test_y=np.asarray([1.84,2.273,3.2,2.831,2.92,3.24,1.35,1.03])input_fn=tf.contrib.learn.io.numpy_input_fn({"X":train_X}, train_y,batch_size=4, num_epochs=2000)test_input_fn=tf.contrib.learn.io.numpy_input_fn({"X":test_X}, test_y)estimator.fit(input_fn=input_fn)W=estimator.get_variable_value('linear/X/weight')[0][0]b=estimator.get_variable_value('linear/bias_weight')[0]("W:", W,"\tb:", b)train_loss=estimator.evaluate(input_fn=input_fn)['loss']test_loss=estimator.evaluate(input_fn=test_input_fn)['loss']("Final training loss:", train_loss)("Final testing loss:", test_loss)
W: 0,252928 b: 0,802972 Perda final de treinamento: 0,153998 Perda de teste final: 0,0777036
Vamos tentar entender o código acima.
- A forma e o tipo de matriz de recursos são declarados usando uma lista. Cada elemento da lista define a estrutura de uma coluna. No exemplo acima, temos apenas 1 recurso que armazena valores reais e foi dado um nome X .
features = [tf.contrib.layers.real_valued_column ("X")] - Então, precisamos de um estimador. Um estimador nada mais é do que um modelo pré-definido com muitos métodos e parâmetros úteis. No exemplo acima, usamos um estimador de modelo de regressão linear.
estimator = tf.contrib.learn.LinearRegressor (feature_columns = features)
- Para fins de treinamento, precisamos usar uma função de entrada que é responsável por alimentar os dados para o estimador durante o treinamento. Leva os valores da coluna de recursos como dicionário. Muitos outros parâmetros, como tamanho do lote, número de épocas, etc., podem ser especificados.
input_fn = tf.contrib.learn.io.numpy_input_fn ({"X": train_X}, train_y, batch_size = 4, num_epochs = 2000) - Para ajustar os dados de treinamento ao estimador, simplesmente usamos o método de ajuste do estimador no qual a função de entrada é passada como um argumento.
estimator.fit (input_fn = input_fn)
- Assim que o treinamento estiver completo, podemos obter o valor de diferentes variáveis usando o método get_variable_value do estimador. Você pode obter uma lista de todas as variáveis usando o método get_variable_names .
W = estimator.get_variable_value ('linear / X / peso') [0] [0] b = estimator.get_variable_value ('linear / bias_weight') [0] - O erro / perda quadrática média pode ser calculado como:
train_loss = estimator.evaluate (input_fn = input_fn) ['perda'] test_loss = estimator.evaluate (input_fn = test_input_fn) ['perda']
Isso nos leva ao final deste artigo de introdução ao TensorFlow !
A partir daqui, você pode tentar explorar este tutorial: MNIST para iniciantes em ML .
Este artigo foi contribuído por Nikhil Kumar . Se você gosta de GeeksforGeeks e gostaria de contribuir, você também pode escrever um artigo usando contribute.geeksforgeeks.org ou enviar o seu artigo para contribute@geeksforgeeks.org. Veja o seu artigo que aparece na página principal do GeeksforGeeks e ajude outros Geeks.
Escreva comentários se encontrar algo incorreto ou se quiser compartilhar mais informações sobre o tópico discutido acima.

As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva