Python | Pandas dataframe.rdiv()
Python é uma ótima linguagem para fazer análise de dados, principalmente por causa do fantástico ecossistema de pacotes python centrados em dados. O Pandas é um desses pacotes e torna a importação e análise de dados muito mais fácil.
Pandas dataframe.rdiv()function compute Divisão flutuante de dataframe e outra, elemento a elemento (operador binário rtruediv). Outro objeto pode ser um escalar, uma série de pandas ou um dataframe de pandas. Esta função é essencialmente igual a fazer, other / dataframemas com suporte para substituir um fill_value para dados ausentes em uma das entradas.
Sintaxe: DataFrame.rdiv (outro, eixo = 'colunas', nível = Nenhum, fill_value = Nenhum)
Parâmetros:
outros: Series, DataFrame ou
eixo constante : Para entrada Series, eixo para corresponder ao índice Series no
nível: Transmitir através de um nível, valores de Índice correspondentes no nível MultiIndex passado
numeric_only: Inclui apenas dados flutuantes, int e booleanos. Válido apenas para objetos DataFrame ou Painel
fill_value: Preencha os valores ausentes (NaN) existentes e qualquer novo elemento necessário para o alinhamento do DataFrame com este valor antes do cálculo. Se os dados em ambos os locais correspondentes do DataFrame estiverem faltando, o resultado estará faltandoRetorna: resultado: DataFrame
Exemplo # 1: Use a rdiv()função para dividir uma série com um dataframe elemento-wise
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]})
# Print the dataframe
df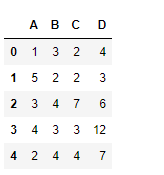
Vamos criar uma série
# importing pandas as pd
import pandas as pd
# Create a series
sr = pd.Series([5, 10, 15, 20], index =["A", "B", "C", "D"])
# Print the series
sr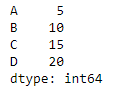
Vamos usar a dataframe.rdiv()função para dividir a série com um dataframe
# perform division of series with
# dataframe element-wise over the column axis
df.rdiv(sr, axis = 1)Saída: 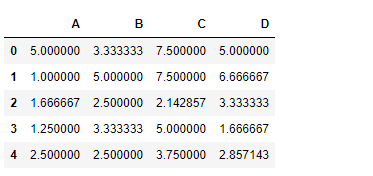
Exemplo # 2: Use a rdiv()função para dividir um dataframe com outro que contém NaNvalor.
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
df1 = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]})
# Creating the second dataframe
df2 = pd.DataFrame({"A":[14, 5, None, 4, 12],
"B":[7, 6, 4, 5, None],
"C":[2, 11, 4, 3, 6],
"D":[4, None, 6, 2, 4]})
# divide df2 by df1 element-wise
# Fill all the missing values by 100
df1.rdiv(df2, fill_value = 100)Saída :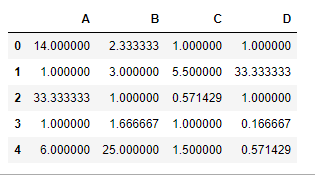
As postagens do blog Acervo Lima te ajudaram? Nos ajude a manter o blog no ar!
Faça uma doação para manter o blog funcionando.
70% das doações são no valor de R$ 5,00...

Diógenes Lima da Silva